
El viernes, Google DeepMind anunció Robotic Transformer 2 (RT-2), un modelo de visión-lenguaje-acción (VLA) «primero en su tipo» que utiliza datos extraídos de Internet para permitir un mejor control robótico a través de comandos de lenguaje sencillo. . El objetivo final es crear robots de propósito general que puedan navegar en entornos humanos, similares a los robots ficticios como WALL-E o C-3PO.
Cuando un ser humano quiere aprender una tarea, a menudo lee y observa. De manera similar, RT-2 utiliza un modelo de lenguaje grande (la tecnología detrás de ChatGPT) que ha sido entrenado en texto e imágenes que se encuentran en línea. RT-2 usa esta información para reconocer patrones y realizar acciones incluso si el robot no ha sido entrenado específicamente para realizar esas tareas, un concepto llamado generalización.
Por ejemplo, Google dice que RT-2 puede permitir que un robot reconozca y tire basura sin haber sido entrenado específicamente para hacerlo. Utiliza su comprensión de lo que es la basura y cómo se desecha normalmente para guiar sus acciones. RT-2 incluso ve los envases de alimentos desechados o las cáscaras de plátano como basura, a pesar de la posible ambigüedad.

En otro ejemplo, The New York Times relata que un ingeniero de Google da la orden «Recoge al animal extinto», y el robot RT-2 localiza y selecciona un dinosaurio de una selección de tres figuritas sobre una mesa.
Esta capacidad es notable porque los robots generalmente han sido entrenados a partir de una gran cantidad de puntos de datos adquiridos manualmente, lo que dificulta ese proceso debido al alto tiempo y costo de cubrir todos los escenarios posibles. En pocas palabras, el mundo real es un caos dinámico, con situaciones cambiantes y configuraciones de objetos. Un ayudante de robot práctico debe poder adaptarse sobre la marcha de maneras que son imposibles de programar explícitamente, y ahí es donde entra en juego el RT-2.
Más de lo que parece
Con RT-2, Google DeepMind ha adoptado una estrategia que aprovecha los puntos fuertes de los modelos de IA transformadores, conocidos por su capacidad para generalizar información. RT-2 se basa en el trabajo anterior de IA en Google, incluido el modelo Pathways Language and Image (PaLI-X) y el modelo Pathways Language Embodied (PaLM-E). Además, RT-2 también recibió capacitación conjunta sobre los datos de su modelo predecesor (RT-1), que fueron recopilados durante un período de 17 meses en un «entorno de cocina de oficina» por 13 robots.
La arquitectura RT-2 implica el ajuste fino de un modelo VLM previamente entrenado en robótica y datos web. El modelo resultante procesa las imágenes de la cámara del robot y predice las acciones que debe ejecutar el robot.
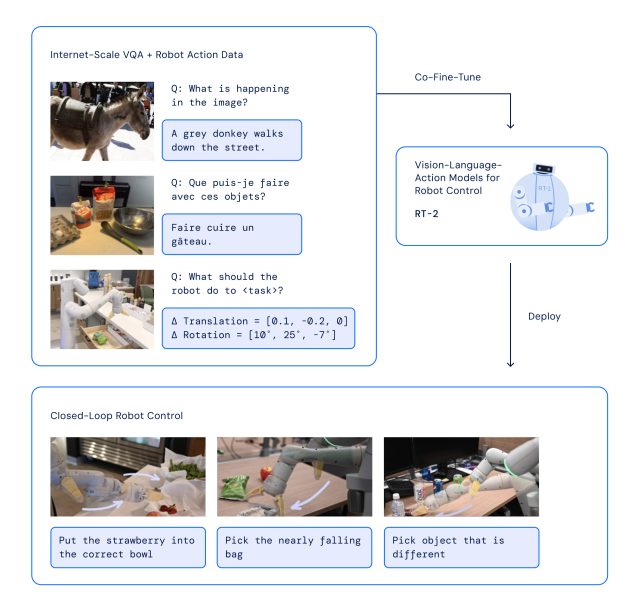
Dado que RT-2 utiliza un modelo de lenguaje para procesar la información, Google optó por representar las acciones como tokens, que tradicionalmente son fragmentos de una palabra. «Para controlar un robot, debe estar entrenado para generar acciones», escribe Google. «Abordamos este desafío al representar acciones como tokens en la salida del modelo, similar a los tokens de lenguaje, y describimos las acciones como cadenas que pueden ser procesadas por tokenizadores de lenguaje natural estándar».
Al desarrollar el RT-2, los investigadores utilizaron el mismo método para dividir las acciones del robot en partes más pequeñas como lo hicieron con la primera versión del robot, el RT-1. Descubrieron que al convertir estas acciones en una serie de símbolos o códigos (una representación de «cadena»), podían enseñarle al robot nuevas habilidades usando los mismos modelos de aprendizaje que usan para procesar datos web.
El modelo también utiliza el razonamiento de cadena de pensamientos, lo que le permite realizar un razonamiento de múltiples etapas, como elegir una herramienta alternativa (una piedra como un martillo improvisado) o elegir la mejor bebida para una persona cansada (una bebida energética).

Google dice que en más de 6000 pruebas, se encontró que RT-2 se desempeñó tan bien como su predecesor, RT-1, en tareas para las que fue entrenado, denominadas tareas «vistas». Sin embargo, cuando se probó con nuevos escenarios «invisibles», RT-2 casi duplicó su rendimiento al 62 por ciento en comparación con el 32 por ciento de RT-1.
Aunque RT-2 muestra una gran capacidad para adaptar lo aprendido a nuevas situaciones, Google reconoce que no es perfecto. En la sección «Limitaciones» del documento técnico de RT-2, los investigadores admiten que si bien la inclusión de datos web en el material de capacitación «impulsa la generalización de los conceptos semánticos y visuales», no otorga mágicamente al robot nuevas habilidades para realizar movimientos físicos que aún no ha aprendido de los datos de entrenamiento de robots de su predecesor. En otras palabras, no puede realizar acciones que no haya practicado físicamente antes, pero mejora en el uso de las acciones que ya conoce de nuevas maneras.
Si bien el objetivo final de Google DeepMind es crear robots de uso general, la empresa sabe que aún queda mucho trabajo de investigación por delante antes de llegar allí. Pero la tecnología como RT-2 parece un gran paso en esa dirección.