
En octubre pasado, un artículo de investigación publicado por un científico de datos de Google, el CTO de Databricks Matei Zaharia y el profesor de UC Berkeley, Pieter Abbeel, postuló una forma de permitir que los modelos GenAI, es decir, modelos similares a GPT-4 y ChatGPT de OpenAI, ingieran mucho más datos de lo que antes era posible. En el estudio, los coautores demostraron que, al eliminar un importante cuello de botella de memoria para los modelos de IA, podrían permitir que los modelos procesen millones de palabras en lugar de cientos de miles, el máximo de los modelos más capaces en ese momento.
Al parecer, la investigación en IA avanza rápidamente.
Hoy, Google anunció el lanzamiento de Gemini 1.5 Pro, el miembro más nuevo de su familia Gemini de modelos GenAI. Diseñado para ser un reemplazo directo de Gemini 1.0 Pro (que anteriormente se llamaba «Gemini Pro 1.0» por razones que sólo conoce el laberíntico brazo de marketing de Google), Gemini 1.5 Pro ha mejorado en varias áreas en comparación con su predecesor, quizás en la mayoría. significativamente en la cantidad de datos que puede procesar.
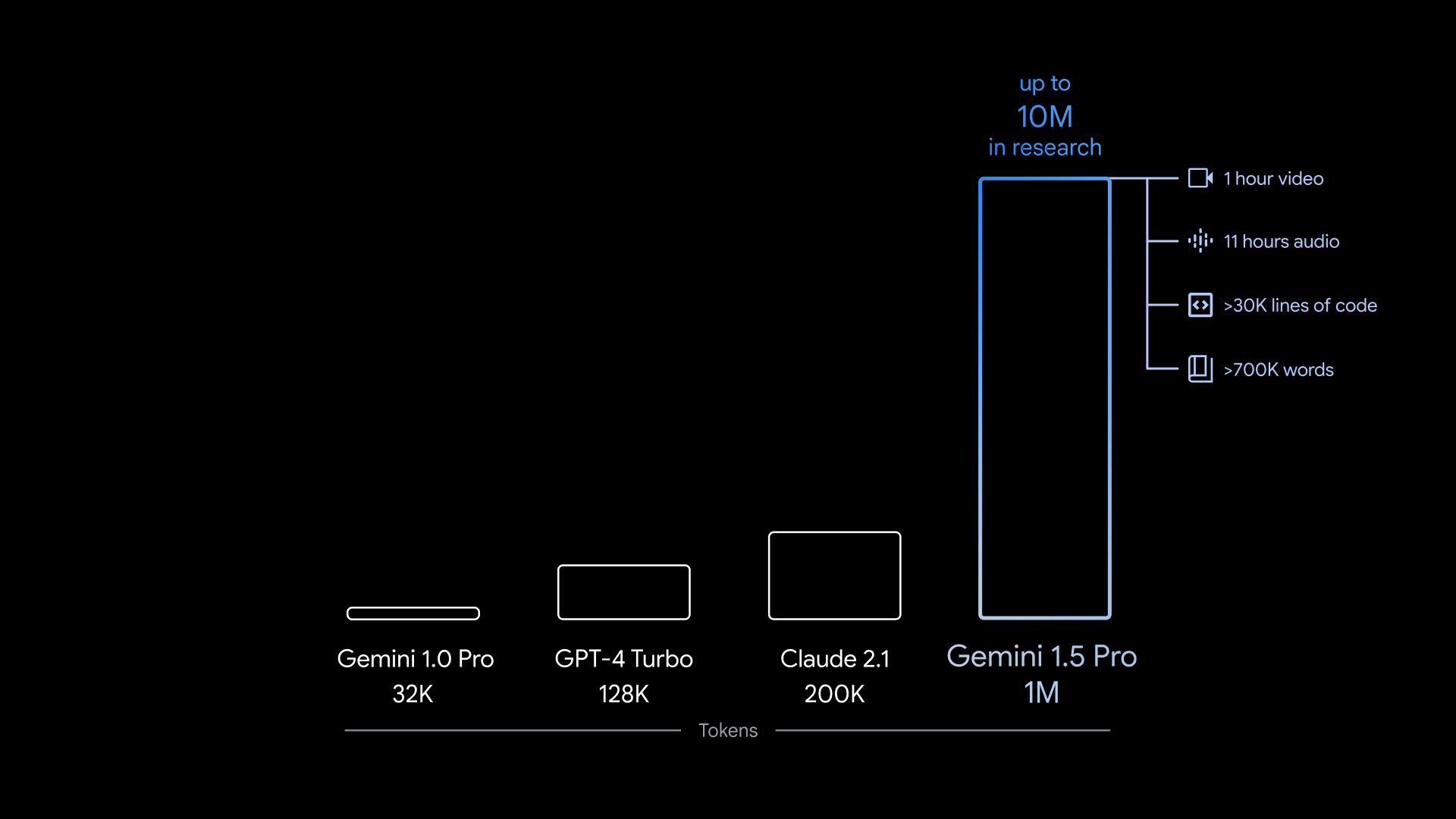
Gemini 1.5 Pro puede admitir ~700.000 palabras o ~30.000 líneas de código: 35 veces la cantidad que Gemini 1.0 Pro puede manejar. Y, dado que el modelo es multimodal, no se limita al texto. Gemini 1.5 Pro puede absorber hasta 11 horas de audio o una hora de vídeo en una variedad de idiomas diferentes.
Créditos de imagen: Google
Para ser claros, ese es un límite superior.
La versión de Gemini 1.5 Pro disponible para la mayoría de los desarrolladores y clientes a partir de hoy (en una vista previa limitada) solo puede procesar ~100 000 palabras a la vez. Google caracteriza el Gemini 1.5 Pro con gran entrada de datos como “experimental”, permitiendo que solo los desarrolladores aprobados como parte de una vista previa privada lo prueben a través de la herramienta de desarrollo GenAI AI Studio de la compañía. Varios clientes que utilizan la plataforma Vertex AI de Google también tienen acceso al Gemini 1.5 Pro de gran capacidad de entrada de datos, pero no todos.
Aún así, el vicepresidente de investigación de Google DeepMind, Oriol Vinyals, lo anunció como un logro.
“Cuando interactúas con [GenAI] En los modelos, la información que ingresa y genera se convierte en el contexto, y cuanto más largas y complejas sean sus preguntas e interacciones, más largo será el contexto con el que el modelo debe poder lidiar”, dijo Vinyals durante una rueda de prensa. «Hemos desbloqueado el contexto largo de una manera bastante masiva».
Gran contexto
El contexto de un modelo, o ventana de contexto, se refiere a los datos de entrada (por ejemplo, texto) que el modelo considera antes de generar resultados (por ejemplo, texto adicional). Una pregunta sencilla: «¿Quién ganó las elecciones presidenciales de Estados Unidos de 2020?» – puede servir como contexto, al igual que el guión de una película, un correo electrónico o un libro electrónico.
Los modelos con ventanas de contexto pequeñas tienden a “olvidar” el contenido incluso de conversaciones muy recientes, lo que los lleva a desviarse del tema, a menudo de manera problemática. Esto no es necesariamente así con modelos con contextos grandes. Como ventaja adicional, los modelos de contexto amplio pueden captar mejor el flujo narrativo de datos que reciben y generar respuestas contextualmente más ricas (al menos hipotéticamente).
Ha habido otros intentos (y experimentos) de modelos con ventanas de contexto atípicamente grandes.
La startup de IA Magic afirmó el verano pasado haber desarrollado un modelo de lenguaje grande (LLM) con una ventana de contexto de 5 millones de tokens. Dos artículos del año pasado detallan arquitecturas de modelos aparentemente capaces de escalar a un millón de tokens, y más. («Los tokens» son fragmentos subdivididos de datos sin procesar, como las sílabas «fan», «tas» y «tic» en la palabra «fantástico»). Y recientemente, un grupo de científicos provenientes de Meta, MIT y Carnegie Mellon desarrollaron un técnica que, según dicen, elimina por completo la restricción sobre el tamaño de la ventana de contexto del modelo.
Pero Google es el primero en hacer disponible comercialmente un modelo con una ventana contextual de este tamaño, superando la ventana contextual de 200.000 tokens del líder anterior Anthropic, si una vista previa privada cuenta como disponible comercialmente.
Créditos de imagen: Google
La ventana de contexto máxima de Gemini 1.5 Pro es de 1 millón de tokens, y la versión del modelo más disponible tiene una ventana de contexto de 128.000 tokens, la misma que el GPT-4 Turbo de OpenAI.
Entonces, ¿qué se puede lograr con una ventana contextual de 1 millón de tokens? Google promete muchas cosas, como analizar una biblioteca de códigos completa, “razonar” documentos extensos como contratos, mantener largas conversaciones con un chatbot y analizar y comparar contenido en videos.
Durante la sesión informativa, Google mostró dos demostraciones pregrabadas de Gemini 1.5 Pro con la ventana contextual de 1 millón de tokens habilitada.
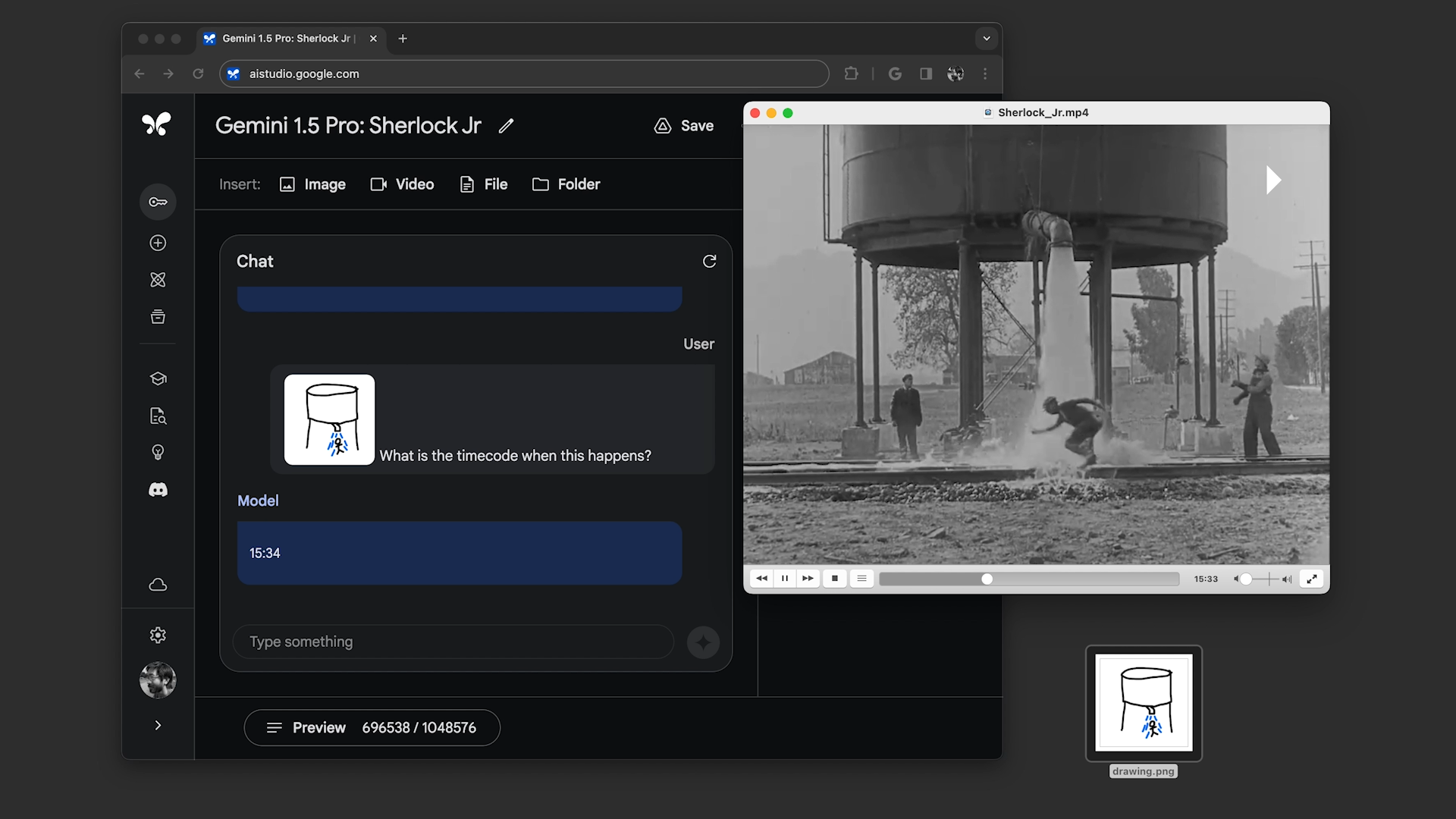
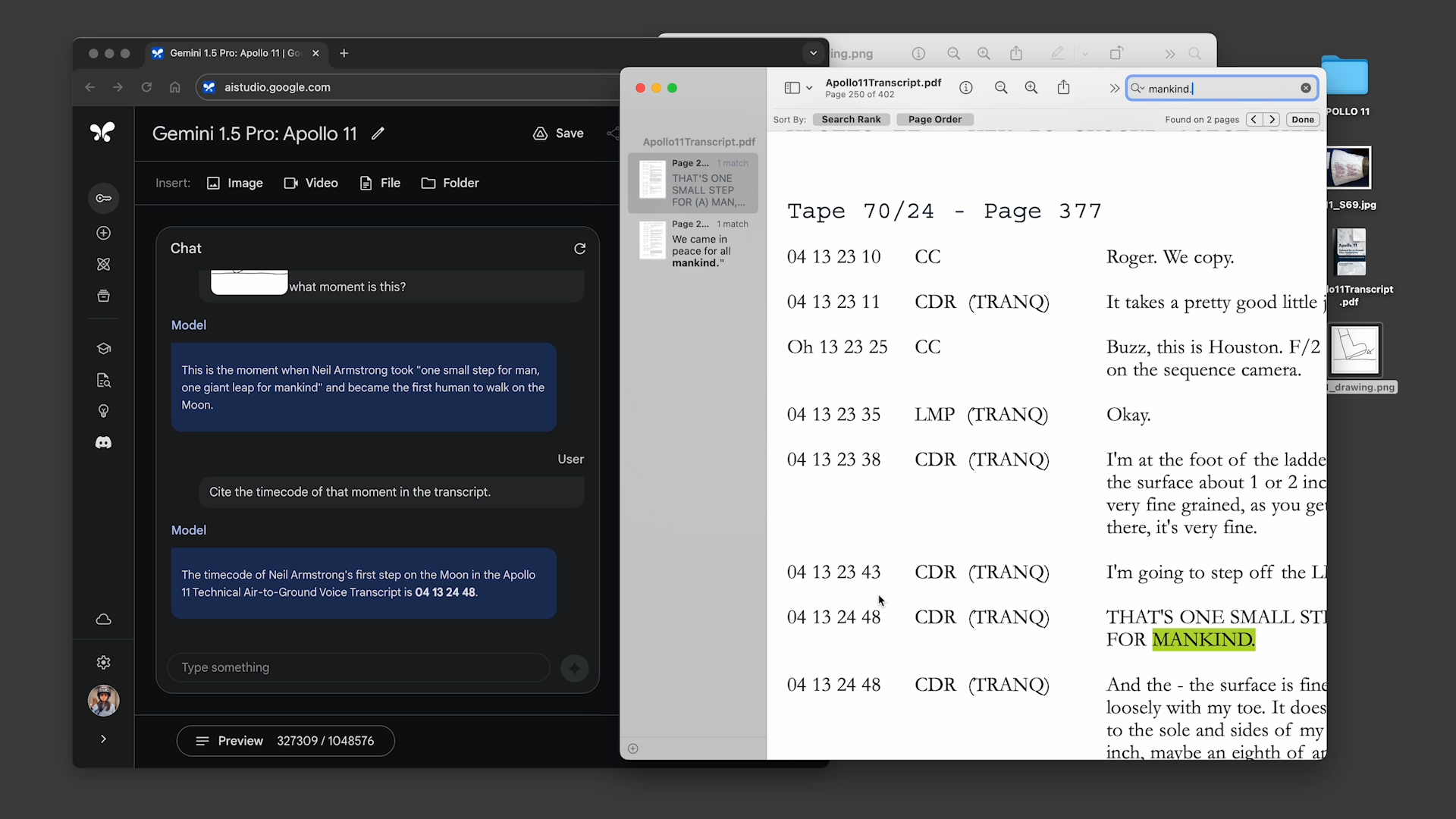
En el primero, el demostrador le pidió a Gemini 1.5 Pro que buscara en la transcripción de la transmisión del aterrizaje lunar del Apolo 11, que tiene alrededor de 402 páginas, citas que contengan chistes, y luego encontrara una escena en la transmisión que se pareciera a un boceto a lápiz. . En el segundo, el manifestante le dijo a la modelo que buscara escenas de “Sherlock Jr.”, la película de Buster Keaton, basándose en descripciones y otro boceto.
Créditos de imagen: Google
Gemini 1.5 Pro completó con éxito todas las tareas que se le solicitaron, pero no particularmente rápido. Cada uno tardó entre 20 segundos y un minuto en procesarse, mucho más que, por ejemplo, la consulta ChatGPT promedio.
Créditos de imagen: Google
Vinyals dice que la latencia mejorará a medida que se optimice el modelo. La compañía ya está probando una versión de Gemini 1.5 Pro con un 10 millones de fichas ventana de contexto.
“El aspecto de latencia [is something] «Estamos… trabajando para optimizarlo; esto todavía se encuentra en una etapa experimental, en una etapa de investigación», dijo. «Así que estos problemas, diría yo, están presentes como en cualquier otro modelo».
Yo no estoy tan seguro de que la latencia pobre sea atractiva para muchas personas, y mucho menos para los clientes que pagan. Tener que esperar minutos a la vez para buscar en un video no suena agradable ni muy escalable en el corto plazo. Y me preocupa cómo se manifiesta la latencia en otras aplicaciones, como las conversaciones de chatbot y el análisis de bases de código. Vinyals no lo dijo, lo que no infunde mucha confianza.
Mi colega más optimista Frédéric Lardinois señaló que la en general El ahorro de tiempo podría hacer que valga la pena jugar con el pulgar. Pero creo que dependerá mucho del caso de uso. ¿Para seleccionar los puntos de la trama de un programa? Talvez no. ¿Pero encontrar la captura de pantalla correcta de una escena de película que sólo recuerdas vagamente? Tal vez.
Otras mejoras
Más allá de la ventana de contexto ampliada, Gemini 1.5 Pro trae a la mesa otras mejoras de calidad de vida.
Google afirma que, en términos de calidad, Gemini 1.5 Pro es «comparable» a la versión actual de Gemini Ultra, el modelo insignia GenAI de Google, gracias a una nueva arquitectura compuesta por modelos «expertos» especializados más pequeños. Gemini 1.5 Pro esencialmente divide las tareas en múltiples subtareas y luego las delega a los modelos expertos apropiados, decidiendo qué tarea delegar en función de sus propias predicciones.
El MoE no es novedoso: de alguna forma existe desde hace años. Pero su eficiencia y flexibilidad lo han convertido en una opción cada vez más popular entre los proveedores de modelos (ver: el modelo que impulsa los servicios de traducción de idiomas de Microsoft).
Ahora bien, “calidad comparable” es una descripción un tanto confusa. La calidad en lo que respecta a los modelos GenAI, especialmente los multimodales, es difícil de cuantificar, y aún más cuando los modelos están ocultos detrás de vistas previas privadas que excluyen a la prensa. Por si sirve de algo, Google afirma que Gemini 1.5 Pro funciona a un «nivel muy similar» en comparación con Ultra en los puntos de referencia que utiliza la compañía para desarrollar LLM mientras superando a Gemini 1.0 Pro en el 87% de ellos puntos de referencia. (Tendré en cuenta que superar a Gemini 1.0 Pro es un listón bajo).
El precio es un gran signo de interrogación.
Durante la vista previa privada, Gemini 1.5 Pro con la ventana contextual de 1 millón de tokens será de uso gratuito, dice Google. Pero la empresa planea introducir niveles de precios en el futuro cercano que comienzan en la ventana de contexto estándar de 128,000 y escalan hasta 1 millón de tokens.
Tengo que imaginar que la ventana de contexto más amplia no será barata, y Google no disipó los temores al optar por no revelar los precios durante la sesión informativa. Si el precio está en línea con el de Anthropic, podría costar $8 por millón de tokens rápidos y $24 por millón de tokens generados. Pero tal vez sea menor; ¡Han sucedido cosas más extrañas! Tendremos que esperar y ver.
También me pregunto qué implicaciones tendrá para el resto de modelos de la familia Gemini, principalmente el Gemini Ultra. ¿Podemos esperar actualizaciones del modelo Ultra más o menos alineadas con las actualizaciones Pro? ¿O siempre habrá, como ocurre ahora, un período incómodo en el que los modelos Pro disponibles sean superiores en rendimiento a los modelos Ultra, que Google todavía comercializa como los mejores de su cartera Gemini?
Si te sientes caritativo, atribuyelo a tus problemas iniciales. Si no es así, llámalo como es: muy confuso.