
Mantenerse al día con una industria que evoluciona tan rápidamente como la IA es una tarea difícil. Entonces, hasta que una IA pueda hacerlo por usted, aquí hay un resumen útil de historias recientes en el mundo del aprendizaje automático, junto con investigaciones y experimentos notables que no cubrimos por sí solos.
La semana pasada, Midjourney, la startup de inteligencia artificial que crea generadores de imágenes (y pronto de video), realizó un pequeño cambio en sus términos de servicio relacionado con la política de la compañía en torno a las disputas de propiedad intelectual. Sirvió principalmente para sustituir el lenguaje jocoso por cláusulas más jurídicas y sin duda basadas en la jurisprudencia. Pero el cambio también puede tomarse como una señal de la convicción de Midjourney de que los proveedores de IA como él saldrán victoriosos en las batallas judiciales con los creadores cuyos trabajos comprenden los datos de capacitación de los proveedores.
El cambio en los términos de servicio de Midjourney.
Los modelos de IA generativa como el de Midjourney se entrenan con una enorme cantidad de ejemplos (por ejemplo, imágenes y texto) generalmente obtenidos de sitios web públicos y repositorios de la web. Los vendedores afirman ese uso justo, la doctrina legal que permite el uso de obras protegidas por derechos de autor para realizar una creación secundaria siempre que sea transformadora, los protege en lo que respecta a la formación de modelos. Pero no todos los creadores están de acuerdo, especialmente a la luz de un número creciente de estudios que muestran que los modelos pueden (y lo hacen) “regurgitar” datos de entrenamiento.
Algunos proveedores han adoptado un enfoque proactivo, firmando acuerdos de licencia con creadores de contenido y estableciendo esquemas de “exclusión voluntaria” para conjuntos de datos de entrenamiento. Otros han prometido que, si los clientes se ven implicados en una demanda por derechos de autor derivada del uso de las herramientas GenAI de un proveedor, no tendrán que pagar honorarios legales.
Midjourney no es uno de los proactivos.
Por el contrario, Midjourney ha sido algo descarado en el uso de obras protegidas por derechos de autor, y en un momento mantuvo una lista de miles de artistas (incluidos ilustradores y diseñadores de grandes marcas como Hasbro y Nintendo) cuyas obras fueron, o serían, utilizadas para entrenar. Los modelos de mitad de viaje. Un estudio muestra evidencia convincente de que Midjourney también utilizó programas de televisión y franquicias de películas en sus datos de entrenamiento, desde “Toy Story” hasta “Star Wars”, “Dune” y “Avengers”.
Ahora bien, existe un escenario en el que las decisiones judiciales finalmente favorecen a Midjourney. Si el sistema de justicia decide que se aplica el uso legítimo, nada impedirá que la startup continúe como hasta ahora, recopilando y entrenando datos protegidos por derechos de autor, antiguos y nuevos.
Pero parece una apuesta arriesgada.
Midjourney está volando alto en este momento, habiendo alcanzado alrededor de $200 millones en ingresos sin un centavo de inversión externa. Sin embargo, los abogados son caros. Y si se decide que el uso legítimo no se aplica en el caso de Midjourney, diezmaría la empresa de la noche a la mañana.
No hay recompensa sin riesgo, ¿eh?
Aquí hay algunas otras historias destacadas de IA de los últimos días:
La publicidad asistida por IA atrae el tipo de atención equivocado: Los creadores en Instagram arremetieron contra un director cuyo comercial reutilizó el trabajo de otro (mucho más difícil e impresionante) sin crédito.
Las autoridades de la UE avisan a las plataformas de inteligencia artificial antes de las elecciones: Están pidiendo a las mayores empresas de tecnología que expliquen su enfoque para prevenir travesuras electorales.
Google Deepmind quiere que su socio de juegos cooperativos sea su IA: Capacitar a un agente durante muchas horas de juego en 3D lo hizo capaz de realizar tareas simples expresadas en lenguaje natural.
El problema con los puntos de referencia: Muchos, muchos proveedores de IA afirman que sus modelos superan o igualan a la competencia mediante alguna métrica objetiva. Pero las métricas que utilizan a menudo son erróneas.
AI2 obtiene 200 millones de dólares: AI2 Incubator, derivada del Instituto Allen para la IA, una organización sin fines de lucro, ha asegurado una ganancia inesperada de 200 millones de dólares en computación que las nuevas empresas que pasan por su programa pueden aprovechar para acelerar el desarrollo temprano.
India requiere, y luego revierte, la aprobación del gobierno para la IA: El gobierno de la India parece no poder decidir qué nivel de regulación es apropiado para la industria de la IA.
Anthropic lanza nuevos modelos: La startup de IA Anthropic ha lanzado una nueva familia de modelos, Claude 3, que, según afirma, rivaliza con el GPT-4 de OpenAI. Pusimos a prueba el modelo insignia (Claude 3 Opus) y lo encontramos impresionante, pero también deficiente en áreas como los eventos actuales.
Falsificaciones políticas: Un estudio del Centro para Contrarrestar el Odio Digital (CCDH), una organización británica sin fines de lucro, analiza el creciente volumen de desinformación generada por IA (específicamente imágenes ultrafalsas relacionadas con elecciones) en X (anteriormente Twitter) durante el año pasado.
OpenAI versus Musk: OpenAI dice que tiene la intención de desestimar todas las afirmaciones hechas por el CEO de X, Elon Musk, en una demanda reciente, y sugirió que el empresario multimillonario, que participó en la cofundación de la empresa, en realidad no tuvo tanto impacto en el desarrollo de OpenAI. Y éxito.
Revisando a Rufus: El mes pasado, Amazon anunció que lanzaría un nuevo chatbot con inteligencia artificial, Rufus, dentro de la aplicación Amazon Shopping para Android e iOS. Obtuvimos acceso temprano y rápidamente nos decepcionó la falta de cosas que Rufus puede hacer (y hacer bien).
Más aprendizajes automáticos
¡Moléculas! ¿Cómo trabajan? Los modelos de IA han sido útiles para nuestra comprensión y predicción de la dinámica molecular, la conformación y otros aspectos del mundo nanoscópico que, de otro modo, requerirían métodos costosos y complejos para probar. Por supuesto, todavía tienes que verificarlo, pero cosas como AlphaFold están cambiando rápidamente el campo.
Microsoft tiene un nuevo modelo llamado ViSNet, destinado a predecir las llamadas relaciones estructura-actividad, relaciones complejas entre moléculas y actividad biológica. Todavía es bastante experimental y definitivamente solo para investigadores, pero siempre es genial ver que los problemas científicos difíciles se abordan con medios tecnológicos de vanguardia.
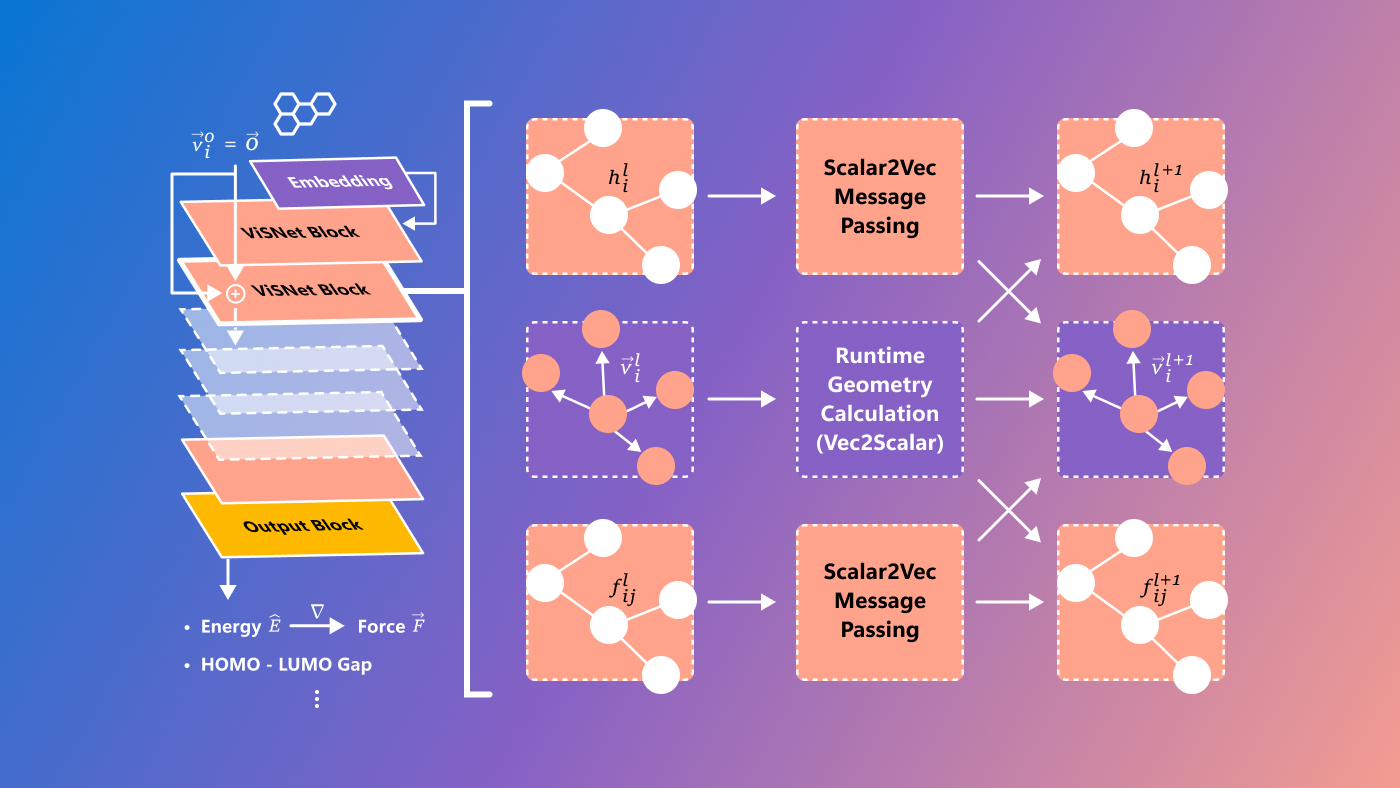
Créditos de imagen: microsoft
Los investigadores de la Universidad de Manchester buscan específicamente identificar y predecir variantes de COVID-19, menos a partir de estructuras puras como ViSNet y más mediante el análisis de conjuntos de datos genéticos muy grandes relacionados con la evolución del coronavirus.
«La cantidad sin precedentes de datos genéticos generados durante la pandemia exige mejoras en nuestros métodos para analizarlos a fondo», dijo el investigador principal, Thomas House. Su colega Roberto Cahuantzi añadió: «Nuestro análisis sirve como prueba de concepto, demostrando el uso potencial de métodos de aprendizaje automático como herramienta de alerta para el descubrimiento temprano de variantes importantes emergentes».
La IA también puede diseñar moléculas, y varios investigadores han firmado una iniciativa que exige seguridad y ética en este campo. Aunque, como señala David Baker (uno de los biofísicos computacionales más destacados del mundo), «los beneficios potenciales del diseño de proteínas superan con creces los peligros en este momento». Bueno, como diseñador de proteínas de IA, él haría dilo. Pero de todos modos, debemos tener cuidado con las regulaciones que no entienden el punto y obstaculizan la investigación legítima, al tiempo que permiten libertad a los malos actores.
Los científicos atmosféricos de la Universidad de Washington han hecho una afirmación interesante basada en el análisis de IA de 25 años de imágenes satelitales sobre Turkmenistán. Esencialmente, la comprensión aceptada de que la agitación económica que siguió a la caída de la Unión Soviética condujo a una reducción de las emisiones puede no ser cierta; de hecho, puede haber ocurrido lo contrario.
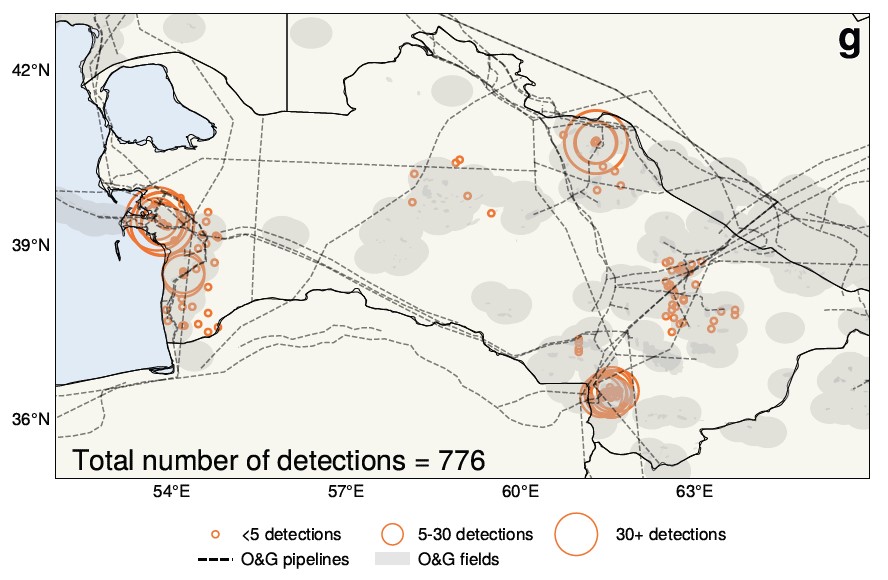
La IA ayudó a encontrar y medir las fugas de metano que se muestran aquí.
«Encontramos que el colapso de la Unión Soviética parece resultar, sorprendentemente, en un aumento de las emisiones de metano», dijo el profesor de la Universidad de Washington, Alex Turner. Los grandes conjuntos de datos y la falta de tiempo para examinarlos hicieron del tema un objetivo natural para la IA, lo que resultó en este cambio inesperado.
Los modelos de idiomas grandes se entrenan en gran medida con datos fuente en inglés, pero esto puede afectar más que su facilidad para usar otros idiomas. Los investigadores de la EPFL que observaron el “lenguaje latente” de LlaMa-2 descubrieron que el modelo aparentemente vuelve al inglés internamente incluso cuando traduce entre francés y chino. Los investigadores sugieren, sin embargo, que esto es más que un proceso de traducción perezoso y, de hecho, el modelo ha estructurado todo su espacio conceptual latente en torno a nociones y representaciones en inglés. ¿Importa? Probablemente. De todos modos, deberíamos diversificar sus conjuntos de datos.