
Meta está agregando otra llama a su manada y ésta sabe codificar. El jueves, Meta presentó «Code Llama», un nuevo modelo de lenguaje grande (LLM) basado en Llama 2 que está diseñado para ayudar a los programadores generando y depurando código. Su objetivo es hacer que el desarrollo de software sea más eficiente y accesible, y es gratuito para uso comercial y de investigación.
Al igual que ChatGPT y GitHub Copilot Chat, puedes pedirle a Code Llama que escriba código usando instrucciones de alto nivel, como «Escríbeme una función que genere la secuencia de Fibonacci». O puede ayudar con la depuración si proporciona una muestra de código problemático y solicita correcciones.
Como extensión de Llama 2 (lanzado en julio), Code Llama se basa en LLM con pesos disponibles que Meta ha estado desarrollando desde febrero. Code Llama ha sido capacitado específicamente en conjuntos de datos de código fuente y puede operar en varios lenguajes de programación, incluidos Python, Java, C++, PHP, TypeScript, C#, secuencias de comandos Bash y más.
En particular, Code Llama puede manejar hasta 100.000 tokens (fragmentos de palabras) de contexto, lo que significa que puede evaluar programas largos. En comparación, ChatGPT normalmente solo funciona con alrededor de 4000 a 8000 tokens, aunque hay modelos de contexto más largos disponibles a través de la API de OpenAI. Como explica Meta en su artículo más técnico:
Además de ser un requisito previo para generar programas más largos, tener secuencias de entrada más largas abre nuevos e interesantes casos de uso para un LLM de código. Por ejemplo, los usuarios pueden proporcionar al modelo más contexto desde su código base para que las generaciones sean más relevantes. También ayuda en escenarios de depuración en bases de código más grandes, donde mantenerse al tanto de todo el código relacionado con un problema concreto puede ser un desafío para los desarrolladores. Cuando los desarrolladores se enfrentan a la depuración de una gran cantidad de código, pueden pasar toda la longitud del código al modelo.
Code Llama de Meta viene en tres tamaños: versiones de 7, 13 y 34 mil millones de parámetros. Los parámetros son elementos numéricos de la red neuronal que se ajustan durante el proceso de entrenamiento (antes del lanzamiento). Más parámetros generalmente significan mayor complejidad y mayor capacidad para tareas matizadas, pero también requieren más potencia computacional para operar.
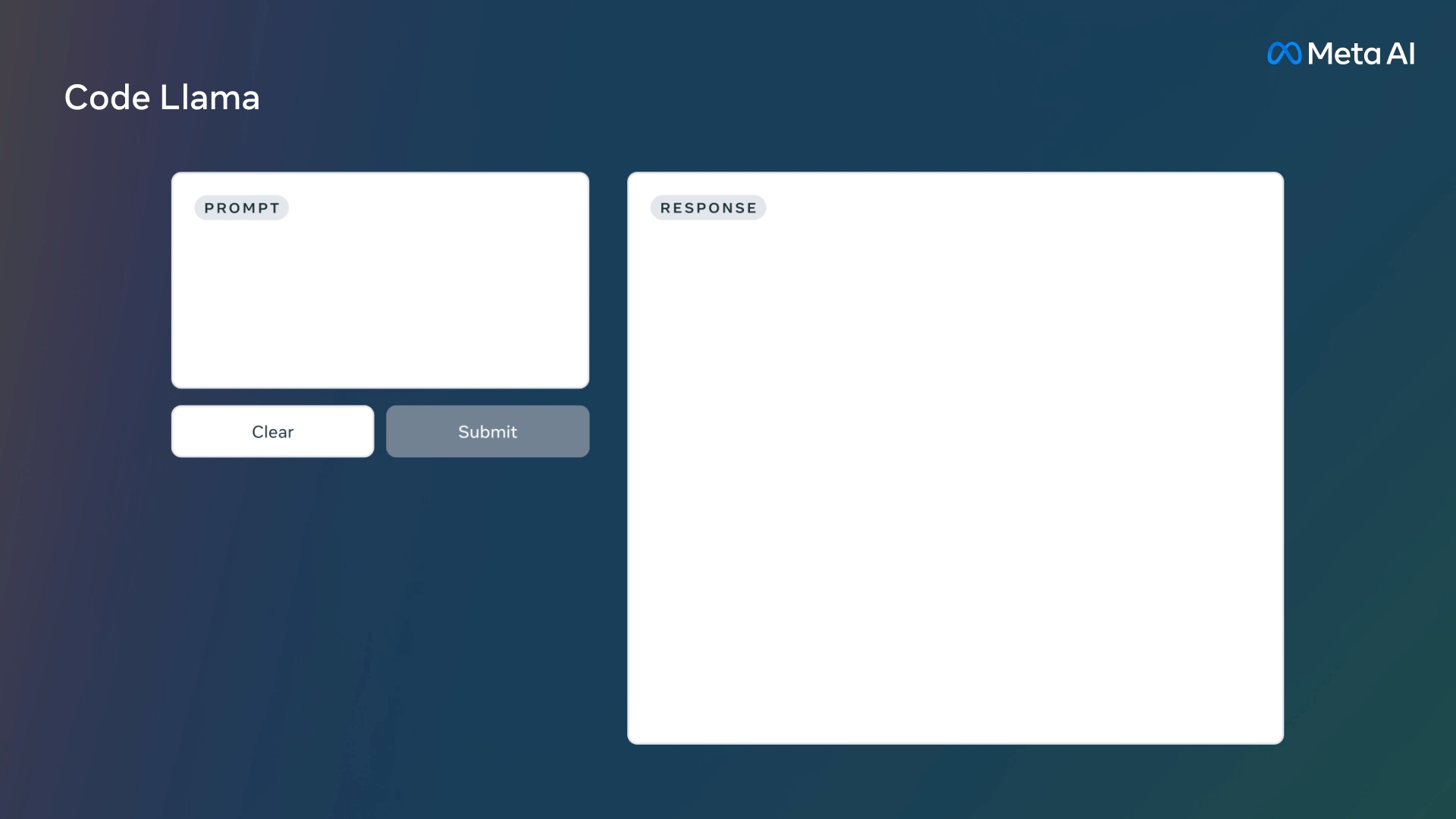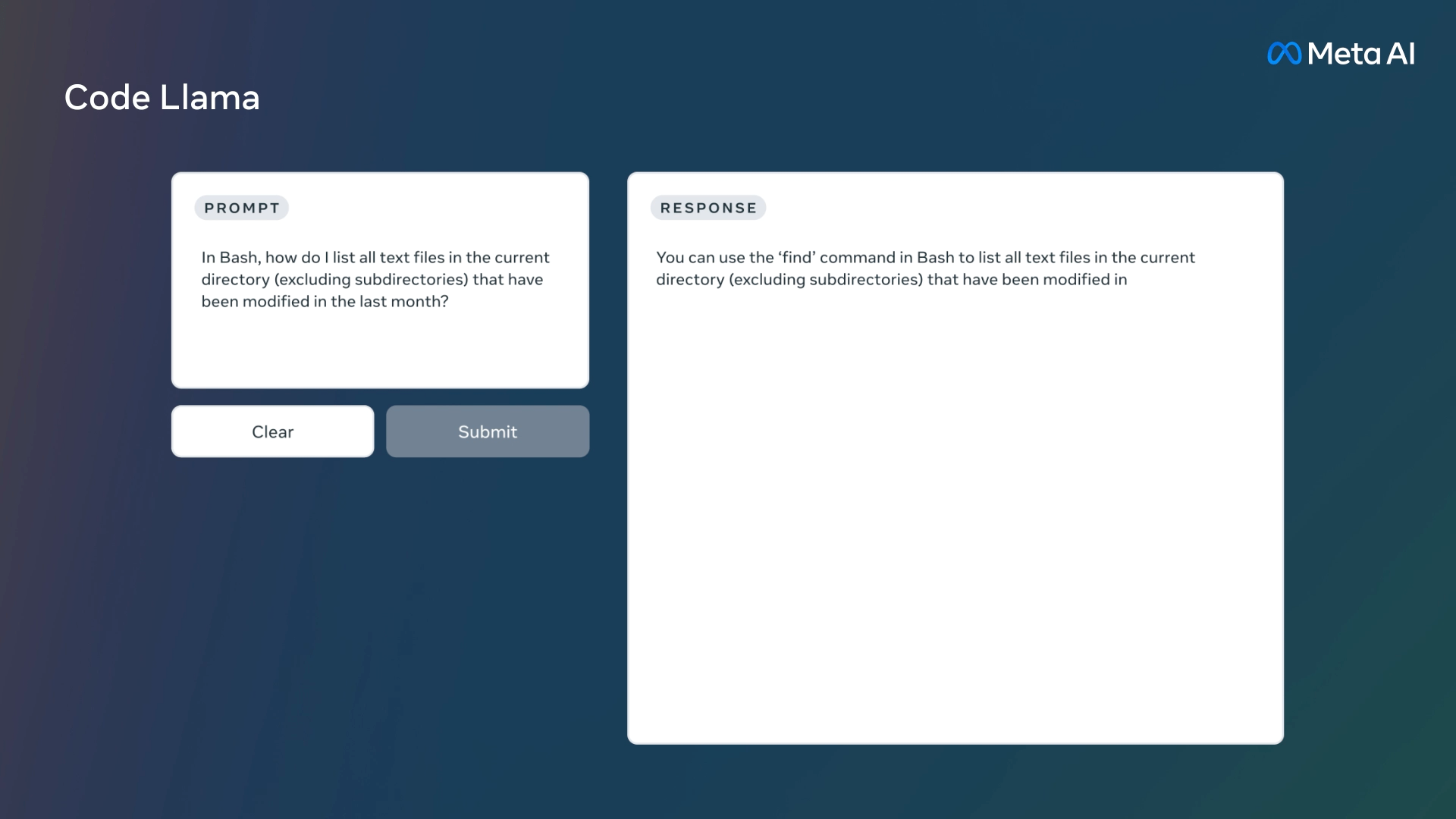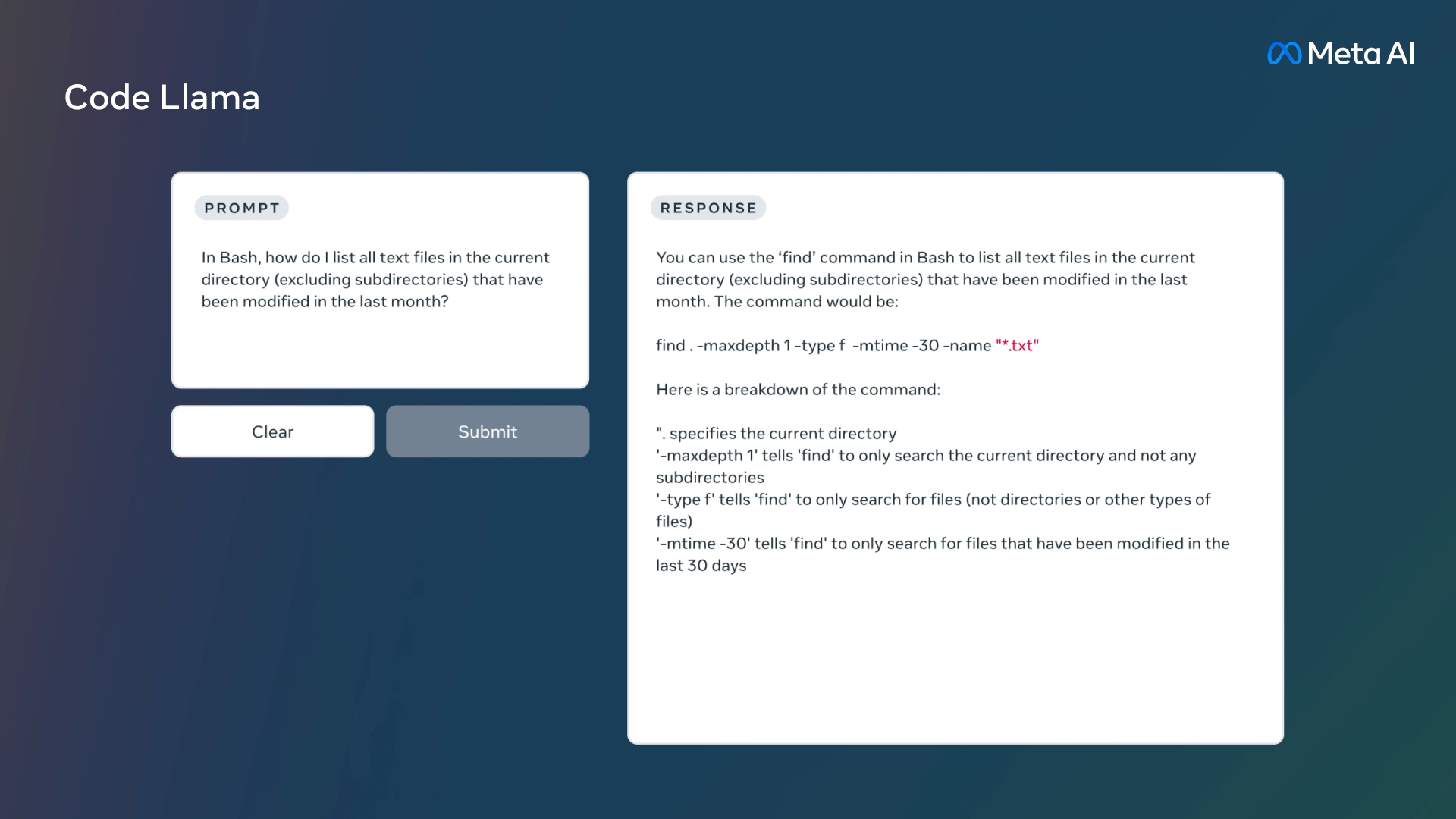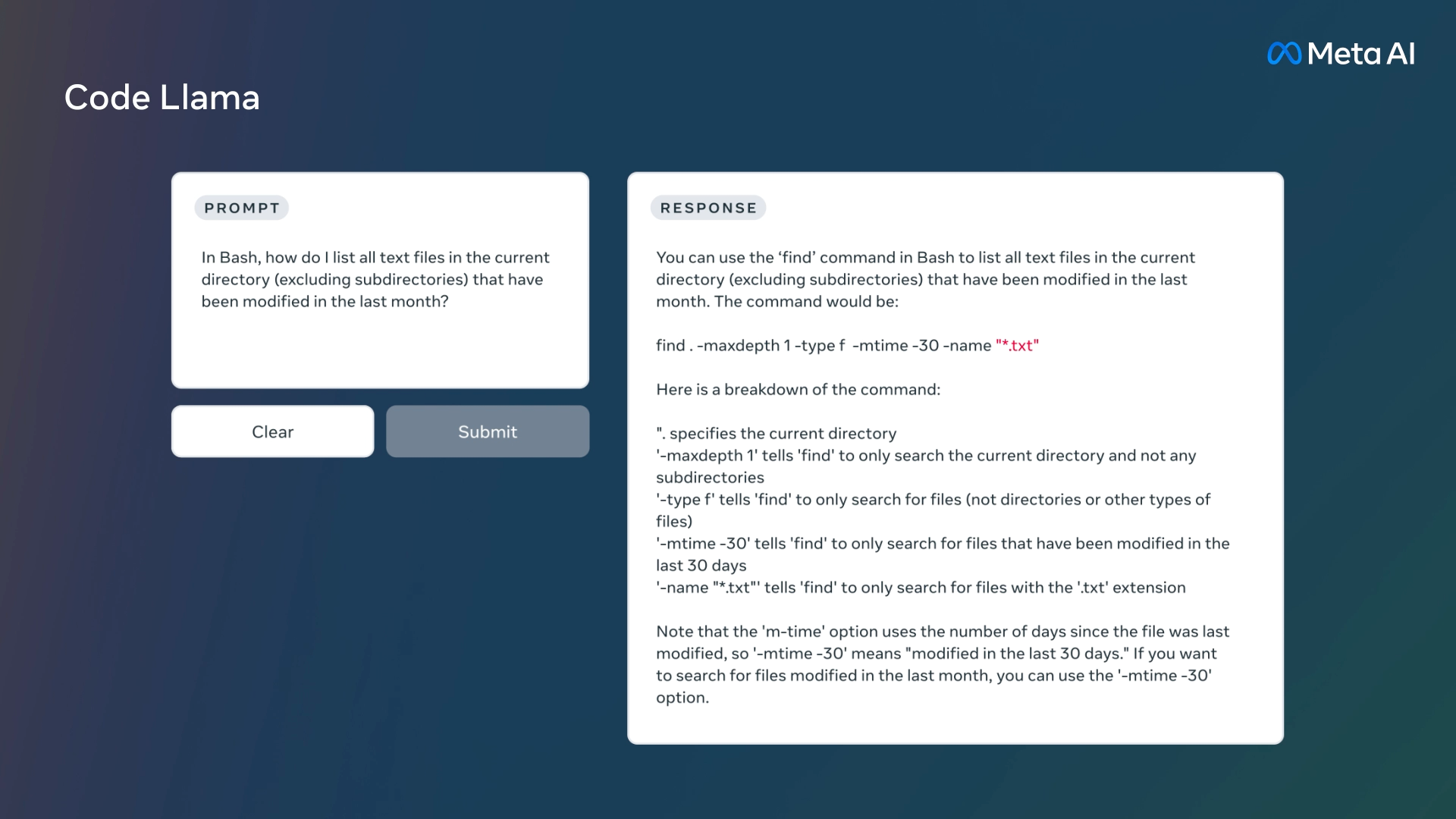
Una demostración de Code Llama proporcionada por Meta.
Meta
Los diferentes tamaños de parámetros ofrecen compensaciones entre velocidad y rendimiento. Si bien se espera que el modelo 34B brinde asistencia de codificación más precisa, es más lento y requiere más memoria y potencia de GPU para funcionar. Por el contrario, los modelos 7B y 13B son más rápidos y más adecuados para tareas que requieren baja latencia, como la finalización de código en tiempo real, y pueden ejecutarse en una única GPU de nivel de consumidor.
Meta también ha lanzado dos variaciones especializadas: Code Llama-Python y Code Llama-Instruct. La variante de Python está optimizada específicamente para la programación de Python («afinada en 100 mil millones de tokens de código Python»), que es un lenguaje importante en la comunidad de IA. Code Llama-Instruct, por otro lado, está diseñado para interpretar mejor la intención del usuario cuando se le proporcionan indicaciones en lenguaje natural.
Además, Meta dice que los modelos base e instrucción 7B y 13B han sido entrenados con la capacidad de «rellenar el medio» (FIM), que les permite insertar código en el código existente, lo que ayuda a completar el código.
Licencia y conjunto de datos
Code Llama está disponible con la misma licencia que Llama 2, que proporciona pesos (los archivos de red neuronal entrenados necesarios para ejecutar el modelo en su máquina) y permite la investigación y el uso comercial, pero con algunas restricciones establecidas en una política de uso aceptable.
Meta ha manifestado repetidamente su preferencia por un enfoque abierto para la IA, aunque su enfoque ha recibido críticas por no ser completamente de «código abierto» de conformidad con la Iniciativa de Código Abierto. Aún así, lo que Meta proporciona y permite con su licencia es mucho más abierto que OpenAI, que no pone a disposición los pesos ni el código para sus modelos de lenguaje de última generación.
Meta no ha revelado la fuente exacta de sus datos de entrenamiento para Code Llama (diciendo que se basa en gran medida en un «conjunto de datos casi deduplicado de código disponible públicamente»), pero algunos sospechar ese contenido extraído del sitio web StackOverflow puede ser una fuente. En X, el científico de datos de Hugging Face, Leandro von Werra, compartió una discusión potencialmente alucinada sobre una función de programación que incluía dos reales Nombres de usuario de StackOverflow.
En el artículo de investigación de Code Llama, Meta dice: «También obtenemos el 8% de nuestros datos de muestra de conjuntos de datos de lenguaje natural relacionados con el código. Este conjunto de datos contiene muchas discusiones sobre código y fragmentos de código incluidos en preguntas o respuestas en lenguaje natural».
Aún así, a von Werra le gustaría que se citaran detalles específicos en el futuro. «Sería fantástico para la reproducibilidad y el intercambio de conocimientos con la comunidad de investigación revelar qué fuentes de datos se utilizaron durante el entrenamiento», escribió von Werra. «Aún más importante, sería fantástico reconocer que estas comunidades contribuyeron al éxito de los modelos resultantes. «