
Imágenes falsas | Benj Edwards
En un artículo de investigación preimpreso titulado «¿GPT-4 pasa la prueba de Turing?», dos investigadores de UC San Diego compararon el modelo de lenguaje de IA GPT-4 de OpenAI con participantes humanos, GPT-3.5 y ELIZA para ver cuál podría engañar a los participantes para que piensen. fue humano con el mayor éxito. Pero en el camino, el estudio, que no ha sido revisado por pares, encontró que los participantes humanos identificaron correctamente a otros humanos en sólo el 63 por ciento de las interacciones, y que un programa informático de la década de 1960 superó el modelo de inteligencia artificial que impulsa la versión gratuita de ChatGPT.
Incluso con las limitaciones y advertencias, que cubriremos a continuación, el documento presenta una comparación que invita a la reflexión entre los enfoques de los modelos de IA y plantea más preguntas sobre el uso de la prueba de Turing para evaluar el rendimiento del modelo de IA.
El matemático e informático británico Alan Turing concibió por primera vez la prueba de Turing como «El juego de la imitación» en 1950. Desde entonces, se ha convertido en un punto de referencia famoso pero controvertido para determinar la capacidad de una máquina para imitar la conversación humana. En las versiones modernas de la prueba, un juez humano normalmente habla con otro humano o con un chatbot sin saber cuál es cuál. Si el juez no puede distinguir de manera confiable al chatbot del humano un cierto porcentaje de las veces, se dice que el chatbot ha pasado la prueba. El umbral para aprobar la prueba es subjetivo, por lo que nunca ha habido un consenso amplio sobre lo que constituiría una tasa de éxito.
En el estudio reciente, incluido en arXiv a finales de octubre, los investigadores de UC San Diego Cameron Jones (estudiante de doctorado en Ciencias Cognitivas) y Benjamin Bergen (profesor del Departamento de Ciencias Cognitivas de la universidad) crearon un sitio web llamado turingtest.live. , donde organizaron una implementación para dos jugadores de la prueba de Turing a través de Internet con el objetivo de ver qué tan bien GPT-4, cuando se le solicitaba de diferentes maneras, podía convencer a la gente de que era humano.
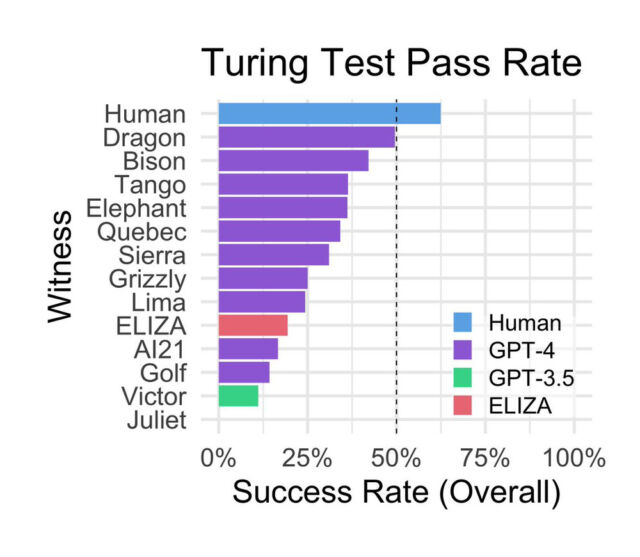
A través del sitio, los interrogadores humanos interactuaron con varios «testigos de IA» que representaban a otros humanos o modelos de IA que incluían los antes mencionados GPT-4, GPT-3.5 y ELIZA, un programa conversacional basado en reglas de la década de 1960. «A los dos participantes en encuentros humanos se les asignaron aleatoriamente los roles de interrogador y testigo», escriben los investigadores. «Los testigos recibieron instrucciones de convencer al interrogador de que eran humanos. Los jugadores emparejados con modelos de IA siempre fueron interrogadores».
En el experimento participaron 652 participantes que completaron un total de 1.810 sesiones, de las cuales 1.405 juegos fueron analizados después de excluir ciertos escenarios como juegos de IA repetidos (lo que lleva a la expectativa de interacciones del modelo de IA cuando otros humanos no estaban en línea) o conocidos personales entre los participantes y testigos, que a veces estaban sentados en la misma habitación.
Sorprendentemente, ELIZA, desarrollado a mediados de la década de 1960 por el informático Joseph Weizenbaum del MIT, obtuvo una puntuación relativamente buena durante el estudio, alcanzando una tasa de éxito del 27 por ciento. GPT-3.5, según la indicación, obtuvo una tasa de éxito del 14 por ciento, por debajo de ELIZA. GPT-4 logró una tasa de éxito del 41 por ciento, solo superada por los humanos reales.
GPT-3.5, el modelo base detrás de la versión gratuita de ChatGPT, ha sido condicionado por OpenAI específicamente para no presentarse como un ser humano, lo que puede explicar en parte su bajo rendimiento. En una publicación en X, el profesor de informática de Princeton, Arvind Narayanan, escribió: «Contexto importante sobre el artículo ‘ChatGPT no pasa la prueba de Turing’. Como siempre, el comportamiento de las pruebas no nos informa sobre la capacidad». En respuesta, continuó: «ChatGPT está ajustado para tener un tono formal, no expresar opiniones, etc., lo que lo hace menos humano. Los autores intentaron cambiar esto con el mensaje, pero tiene límites. La mejor manera de «Pretender ser un ser humano chateando es afinar los registros de chat humanos».
Además, los autores especulan sobre las razones del relativo éxito de ELIZA en el estudio:
«En primer lugar, las respuestas de ELIZA tienden a ser conservadoras. Si bien esto generalmente da la impresión de un interlocutor que no coopera, impide que el sistema proporcione señales explícitas como información incorrecta o conocimiento oscuro. En segundo lugar, ELIZA no muestra el tipo de señales que los interrogadores han llegado a asociarse con los asistentes de LLM, como ser servicial, amigable y detallado. Finalmente, algunos interrogadores informaron que pensaban que ELIZA era «una lástima» para ser un modelo de IA actual y, por lo tanto, era más probable que fuera un ser humano que intencionalmente no cooperaba. «.
Durante las sesiones, las estrategias más comunes utilizadas por los interrogadores incluyeron charlas triviales y preguntas sobre conocimientos y acontecimientos actuales. Las estrategias más exitosas implicaron hablar en un idioma distinto del inglés, preguntar sobre la hora o los acontecimientos actuales y acusar directamente al testigo de ser un modelo de IA.
Los participantes emitieron sus juicios basándose en las respuestas que recibieron. Curiosamente, el estudio encontró que los participantes basaron sus decisiones principalmente en el estilo lingüístico y los rasgos socioemocionales, en lugar de solo en la percepción de la inteligencia. Los participantes notaron cuando las respuestas eran demasiado formales o informales, o cuando las respuestas carecían de individualidad o parecían genéricas. El estudio también mostró que la educación y la familiaridad de los participantes con los modelos de lenguaje grandes (LLM) no predijeron significativamente su éxito en la detección de IA.

Jones y Bergen, 2023
Los autores del estudio reconocen las limitaciones del estudio, incluido el posible sesgo de la muestra al reclutar en las redes sociales y la falta de incentivos para los participantes, lo que puede haber llevado a que algunas personas no cumplieran el rol deseado. También dicen que sus resultados (especialmente el desempeño de ELIZA) pueden respaldar las críticas comunes a la prueba de Turing como una forma inexacta de medir la inteligencia de las máquinas. «Sin embargo», escriben, «sostenemos que la prueba sigue siendo relevante como marco para medir la interacción social fluida y el engaño, y para comprender las estrategias humanas para adaptarse a estos dispositivos».