
Ars Technica
El jueves, un par de aficionados a la tecnología lanzaron Riffusion, un modelo de IA que genera música a partir de indicaciones de texto al crear una representación visual del sonido y convertirlo en audio para su reproducción. Utiliza una versión mejorada del modelo de síntesis de imágenes Stable Diffusion 1.5, que aplica la difusión latente visual al procesamiento de sonido de una manera novedosa.
Creado como un proyecto de pasatiempo por Seth Forsgren y Hayk Martiros, Riffusion funciona generando sonogramas, que almacenan audio en una imagen bidimensional. En un sonograma, el eje X representa el tiempo (el orden en que se reproducen las frecuencias, de izquierda a derecha) y el eje Y representa la frecuencia de los sonidos. Mientras tanto, el color de cada píxel en la imagen representa la amplitud del sonido en ese momento dado.
Dado que un sonograma es un tipo de imagen, Stable Diffusion puede procesarlo. Forsgren y Martiros entrenaron un modelo de difusión estable personalizado con sonogramas de ejemplo vinculados a descripciones de los sonidos o géneros musicales que representaban. Con ese conocimiento, Riffusion puede generar nueva música sobre la marcha basándose en indicaciones de texto que describen el tipo de música o sonido que desea escuchar, como «jazz», «rock» o incluso escribiendo en un teclado.
Después de generar la imagen del sonograma, Riffusion usa Torchaudio para cambiar el sonograma a sonido y reproducirlo como audio.
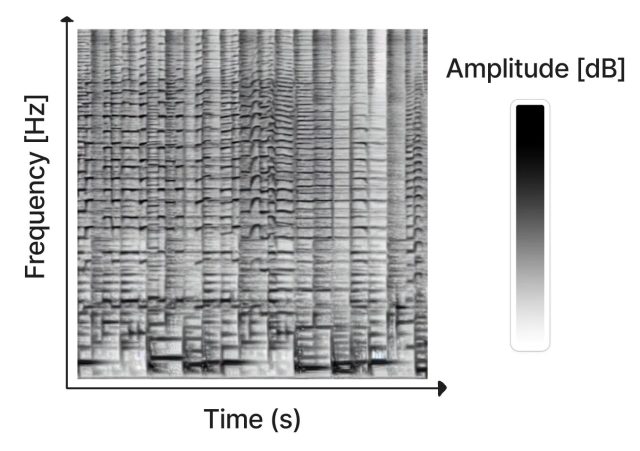
«Este es el modelo de difusión estable v1.5 sin modificaciones, simplemente ajustado en imágenes de espectrogramas emparejados con texto», escriben los creadores de Riffusion en su página de explicación. «Puede generar infinitas variaciones de un aviso variando la semilla. Todas las mismas interfaces de usuario web y técnicas como img2img, inpainting, avisos negativos e interpolación funcionan de manera inmediata».
Los visitantes del sitio web de Riffusion pueden experimentar con el modelo de IA gracias a una aplicación web interactiva que genera sonogramas interpolados (unificados suavemente para una reproducción ininterrumpida) en tiempo real mientras visualizan el espectrograma continuamente en el lado izquierdo de la página.
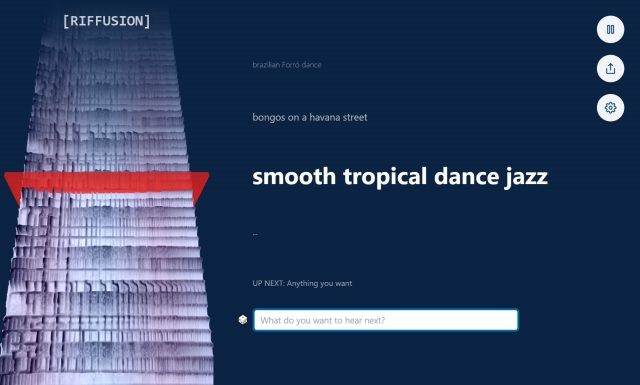
También puede fusionar estilos. Por ejemplo, escribir «jazz de baile tropical suave» trae elementos de diferentes géneros para un resultado novedoso, fomentando la experimentación mediante la combinación de estilos.
Por supuesto, Riffusion no es el primer generador de música impulsado por IA. A principios de este año, Harmonai lanzó Dance Diffusion, un modelo de música generativa impulsado por IA. Jukebox de OpenAI, anunciado en 2020, también genera nueva música con una red neuronal. Y sitios web como Soundraw crean música sin parar sobre la marcha.
En comparación con esos esfuerzos musicales de IA más optimizados, Riffusion se siente más como el proyecto de pasatiempo que es. La música que genera varía de interesante a ininteligible, pero sigue siendo una aplicación notable de la tecnología de difusión latente que manipula el audio en un espacio visual.
El código y el punto de control del modelo de Riffusion están disponibles en GitHub.