
El lunes, Mistral AI anunció un nuevo modelo de lenguaje de IA llamado Mixtral 8x7B, un modelo de «mezcla de expertos» (MoE) con pesos abiertos que, según se informa, realmente iguala el rendimiento del GPT-3.5 de OpenAI, un logro que otros han reclamado en el pasado. pero los pesos pesados de la IA, como Andrej Karpathy y Jim Fan de OpenAI, lo toman en serio. Eso significa que estamos más cerca de tener un asistente de inteligencia artificial de nivel ChatGPT-3.5 que pueda ejecutarse libre y localmente en nuestros dispositivos, si se implementa correctamente.
Mistral, con sede en París y fundada por Arthur Mensch, Guillaume Lample y Timothée Lacroix, ha experimentado un rápido aumento en el espacio de la IA recientemente. Ha estado recaudando rápidamente capital de riesgo hasta convertirse en una especie de anti-OpenAI francés, defendiendo modelos más pequeños con un rendimiento llamativo. En particular, los modelos de Mistral se ejecutan localmente con pesos abiertos que se pueden descargar y utilizar con menos restricciones que los modelos cerrados de IA de OpenAI, Anthropic o Google. (En este contexto, los «pesos» son los archivos de computadora que representan una red neuronal entrenada).
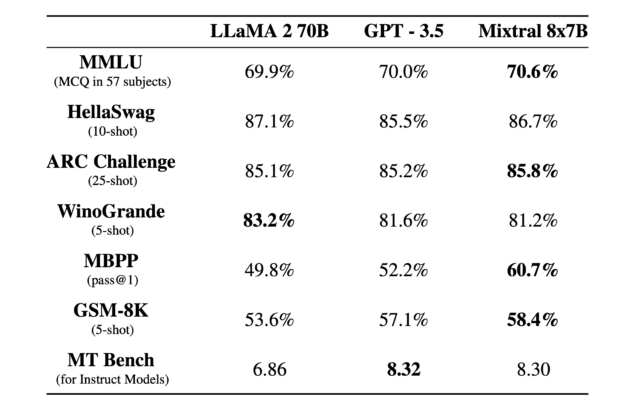
Mixtral 8x7B puede procesar una ventana de contexto de token de 32K y funciona en francés, alemán, español, italiano e inglés. Funciona de manera muy similar a ChatGPT en el sentido de que puede ayudar con tareas de composición, analizar datos, solucionar problemas de software y escribir programas. Mistral afirma que supera al modelo de lenguaje grande LLaMA 2 70B (70 mil millones de parámetros) mucho más grande de Meta y que iguala o supera al GPT-3.5 de OpenAI en ciertos puntos de referencia, como se ve en el cuadro a continuación.
Mistral
La velocidad a la que los modelos de IA de peso abierto alcanzaron a la mejor oferta de OpenAI hace un año ha tomado a muchos por sorpresa. Pietro Schirano, fundador de EverArt, escribió en X: «Simplemente increíble. Estoy ejecutando la instrucción Mistral 8x7B a 27 tokens por segundo, completamente localmente gracias a @LMStudioAI. Un modelo que obtiene una puntuación mejor que GPT-3.5, localmente. Imagínese dónde estamos. Será dentro de 1 año.»
El fundador de LexicaArt, Sharif Shameem, tuiteó: «El modelo Mixtral MoE realmente se siente como un punto de inflexión: un verdadero modelo de nivel GPT-3.5 que puede ejecutarse a 30 tokens/seg en un M1. Imagine todos los productos ahora posibles cuando la inferencia es 100 % gratuita y tus datos permanecen en tu dispositivo.» A lo que Andrej Karpathy respondió: «De acuerdo. Parece que la capacidad/poder de razonamiento ha dado grandes pasos, lo que se queda atrás es más la UI/UX de todo el asunto, tal vez alguna herramienta use ajustes, tal vez algunas bases de datos RAG, etc.»
Mezcla de expertos
Entonces, ¿qué significa mezcla de expertos? Como explica esta excelente guía de Hugging Face, se refiere a una arquitectura de modelo de aprendizaje automático donde una red de puerta enruta los datos de entrada a diferentes componentes especializados de la red neuronal, conocidos como «expertos», para su procesamiento. La ventaja de esto es que permite un entrenamiento e inferencia de modelos más eficiente y escalable, ya que solo se activa un subconjunto de expertos para cada entrada, lo que reduce la carga computacional en comparación con los modelos monolíticos con recuentos de parámetros equivalentes.
En términos sencillos, un Ministerio de Educación es como tener un equipo de trabajadores especializados (los «expertos») en una fábrica, donde un sistema inteligente (la «red de puertas») decide qué trabajador es el más adecuado para realizar cada tarea específica. Esta configuración hace que todo el proceso sea más eficiente y rápido, ya que cada tarea la realiza un experto en esa área y no todos los trabajadores necesitan participar en todas las tareas, a diferencia de una fábrica tradicional donde cada trabajador puede tener que hacer un poco de trabajo. todo.
Se rumorea que OpenAI utiliza un sistema MoE con GPT-4, lo que explica parte de su rendimiento. En el caso de Mixtral 8x7B, el nombre implica que el modelo es una mezcla de ocho redes neuronales de 7 mil millones de parámetros, pero como Karpathy puntiagudo en un tweet, el nombre es un poco engañoso porque «no son todos los parámetros 7B los que se modifican 8x, solo los bloques FeedForward en el Transformer se modifican 8x, todo lo demás permanece igual. De ahí también por qué el número total de params no es 56B sino solo 46.7B.»
Mixtral no es el primer modelo de mezcla «abierta» de expertos, pero destaca por su tamaño relativamente pequeño en número de parámetros y rendimiento. Ya está disponible en Hugging Face y BitTorrent bajo la licencia Apache 2.0. La gente lo ha estado ejecutando localmente usando una aplicación llamada LM Studio. Además, Mistral comenzó a ofrecer acceso beta a una API para tres niveles de modelos Mistral el lunes.