
Mantenerse al día con una industria que evoluciona tan rápidamente como la IA es una tarea difícil. Entonces, hasta que una IA pueda hacerlo por usted, aquí hay un resumen útil de historias recientes en el mundo del aprendizaje automático, junto con investigaciones y experimentos notables que no cubrimos por sí solos.
Esta semana en IA, me gustaría centrar la atención en las startups de etiquetado y anotación: startups como Scale AI, que supuestamente está en conversaciones para recaudar nuevos fondos con una valoración de 13.000 millones de dólares. Es posible que las plataformas de etiquetado y anotación no llamen la atención sobre los nuevos y llamativos modelos de IA generativa como lo hace Sora de OpenAI. Pero son esenciales. Sin ellos, podría decirse que los modelos modernos de IA no existirían.
Los datos con los que se entrenan muchos modelos deben etiquetarse. ¿Por qué? Las etiquetas ayudan a los modelos a comprender e interpretar los datos durante el proceso de capacitación. Por ejemplo, las etiquetas para entrenar un modelo de reconocimiento de imágenes pueden tomar la forma de marcas alrededor de objetos, «cuadros delimitadores» o leyendas que hacen referencia a cada persona, lugar u objeto representado en una imagen.
La precisión y la calidad de las etiquetas afectan significativamente el rendimiento (y la confiabilidad) de los modelos entrenados. Y la anotación es una tarea enorme, que requiere de miles a millones de etiquetas para los conjuntos de datos más grandes y sofisticados que se utilizan.
Por lo tanto, uno pensaría que los anotadores de datos recibirían un buen trato, se les pagaría salarios dignos y se les darían los mismos beneficios que disfrutan los ingenieros que construyen los modelos. Pero a menudo ocurre lo contrario: producto de las brutales condiciones laborales que fomentan muchas empresas emergentes de anotación y etiquetado.
Empresas con miles de millones en el banco, como OpenAI, han dependido de anotadores en países del tercer mundo a los que se les paga sólo unos pocos dólares por hora. Algunos de estos anotadores están expuestos a contenido muy perturbador, como imágenes gráficas, pero no se les da tiempo libre (ya que normalmente son contratistas) ni acceso a recursos de salud mental.
Un artículo excelente en NY Mag abre las cortinas sobre Scale AI en particular, que recluta anotadores en países tan remotos como Nairobi y Kenia. Algunas de las tareas en Scale AI requieren para los etiquetadores varias jornadas laborales de ocho horas, sin descansos, y pagan tan solo 10 dólares. Y estos trabajadores están en deuda con los caprichos de la plataforma. Los anotadores a veces pasan largos períodos sin recibir trabajo, o son expulsados sin ceremonias de Scale AI, como les sucedió recientemente a los contratistas en Tailandia, Vietnam, Polonia y Pakistán.
Algunas plataformas de anotación y etiquetado afirman ofrecer trabajo de “comercio justo”. De hecho, lo han convertido en una parte central de su marca. Pero como señala Kate Kaye de MIT Tech Review, no existen regulaciones, sólo estándares industriales débiles sobre lo que significa el trabajo de etiquetado ético, y las propias definiciones de las empresas varían ampliamente.
¿Entonces lo que hay que hacer? Salvo que se produzca un avance tecnológico masivo, la necesidad de anotar y etiquetar datos para el entrenamiento de IA no desaparecerá. Podemos esperar que las plataformas se autorregulan, pero la solución más realista parece ser la formulación de políticas. Esta es una perspectiva complicada en sí misma, pero yo diría que es la mejor oportunidad que tenemos de cambiar las cosas para mejor. O al menos empezando a hacerlo.
Aquí hay algunas otras historias destacadas de IA de los últimos días:
-
- OpenAI crea un clonador de voz: OpenAI está presentando una nueva herramienta impulsada por IA que desarrolló, Voice Engine, que permite a los usuarios clonar una voz a partir de una grabación de 15 segundos de alguien hablando. Pero la compañía ha decidido no publicarlo ampliamente (todavía), citando riesgos de mal uso y abuso.
- Amazon duplica su apuesta por Anthropic: Amazon ha invertido otros 2.750 millones de dólares en el creciente poder de IA de Anthropic, siguiendo con la opción que dejó abierta en septiembre pasado.
- Google.org lanza una aceleradora: Google.org, el ala caritativa de Google, está lanzando un nuevo programa de seis meses de duración por valor de 20 millones de dólares para ayudar a financiar a organizaciones sin fines de lucro que desarrollan tecnología que aprovecha la IA generativa.
- Una nueva arquitectura de modelo: La startup de IA AI21 Labs ha lanzado un modelo de IA generativa, Jamba, que emplea una arquitectura de modelo nueva y novedosa (modelos de espacio de estados o SSM) para mejorar la eficiencia.
- Databricks lanza DBRX: En otras noticias sobre modelos, Databricks lanzó esta semana DBRX, un modelo de IA generativa similar a la serie GPT de OpenAI y Gemini de Google. La compañía afirma que logra resultados de última generación en una serie de puntos de referencia de IA populares, incluidos varios razonamientos de medición.
- Uber Eats y la regulación de la IA en el Reino Unido: Natasha escribe sobre cómo la lucha de un mensajero de Uber Eats contra el sesgo de la IA muestra que la justicia bajo las regulaciones de IA del Reino Unido se logra con esfuerzo.
- Guía de seguridad electoral de la UE: La Unión Europea publicó el martes un proyecto de directrices de seguridad electoral dirigidas a todo el mundo. dos docenas plataformas reguladas bajo la Ley de Servicios Digitales, que incluye directrices relativas a la prevención de que los algoritmos de recomendación de contenidos difundan desinformación generativa basada en IA (también conocida como deepfakes políticos).
- Grok se actualiza: El chatbot Grok de X pronto obtendrá un modelo subyacente actualizado, Grok-1.5; al mismo tiempo, todos los suscriptores Premium de X obtendrán acceso a Grok. (Grok anteriormente era exclusivo para los clientes de X Premium+).
- Adobe amplía Firefly: Esta semana, Adobe presentó los servicios Firefly, un conjunto de más de 20 nuevas API, herramientas y servicios generativos y creativos. También lanzó Custom Models, que permite a las empresas ajustar los modelos de Firefly en función de sus activos, una parte de la nueva suite GenStudio de Adobe.
Más aprendizajes automáticos
¿Cómo está el clima? La IA es cada vez más capaz de decirte esto. Hace unos meses noté algunos esfuerzos en el pronóstico a escala horaria, semanal y centenaria, pero como todo lo relacionado con la IA, el campo avanza rápidamente. Los equipos detrás de MetNet-3 y GraphCast han publicado un artículo que describe un nuevo sistema llamado SEEDS, para Scalable Ensemble Sobre Diffusion Sampler.
Animación que muestra cómo más predicciones crean una distribución más uniforme de las predicciones meteorológicas.
SEEDS utiliza la difusión para generar «conjuntos» de resultados meteorológicos plausibles para un área basándose en los datos de entrada (quizás lecturas de radar o imágenes orbitales) mucho más rápido que los modelos basados en la física. Con un mayor número de conjuntos, pueden cubrir más casos extremos (como un evento que solo ocurre en 1 de cada 100 escenarios posibles) y tener más confianza en situaciones más probables.
Fujitsu también espera comprender mejor el mundo natural aplicando técnicas de manejo de imágenes de IA a imágenes submarinas y datos lidar recopilados por vehículos autónomos submarinos. Mejorar la calidad de las imágenes permitirá que otros procesos menos sofisticados (como la conversión 3D) funcionen mejor con los datos de destino.
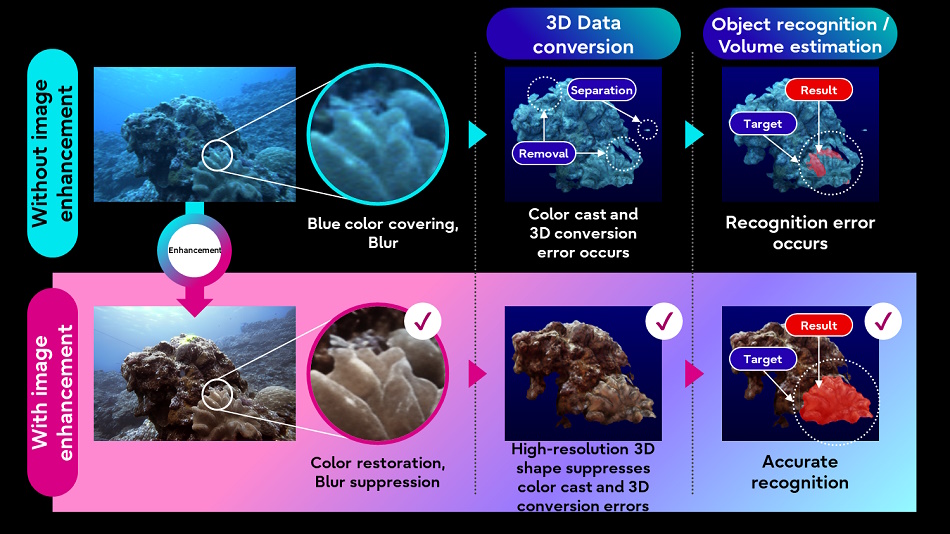
Créditos de imagen: fujitsu
La idea es construir un “gemelo digital” de aguas que pueda ayudar a simular y predecir nuevos desarrollos. Estamos muy lejos de eso, pero hay que empezar por algún lado.
Entre los LLM, los investigadores han descubierto que imitan la inteligencia mediante un método incluso más simple de lo esperado: funciones lineales. Francamente, las matemáticas me superan (cosas vectoriales en muchas dimensiones), pero este artículo del MIT deja bastante claro que el mecanismo de recuperación de estos modelos es bastante… básico.
Aunque estos modelos son funciones no lineales realmente complicadas que se entrenan con una gran cantidad de datos y son muy difíciles de entender, a veces hay mecanismos realmente simples trabajando dentro de ellos. Este es un ejemplo de eso”, dijo el coautor principal Evan Hernández. Si tiene una mentalidad más técnica, consulte el documento aquí.
Una forma en que estos modelos pueden fallar es no comprender el contexto o la retroalimentación. Incluso un LLM realmente capaz podría no “entenderlo” si le dice que su nombre se pronuncia de cierta manera, ya que en realidad no saben ni entienden nada. En los casos en los que eso podría ser importante, como las interacciones entre humanos y robots, podría desanimar a las personas si el robot actúa de esa manera.
Disney Research ha estado investigando las interacciones automatizadas de los personajes durante mucho tiempo, y este artículo sobre pronunciación y reutilización de nombres apareció hace un tiempo. Parece obvio, pero extraer los fonemas cuando alguien se presenta y codificarlos en lugar de solo el nombre escrito es un enfoque inteligente.

Créditos de imagen: Investigación de Disney
Por último, a medida que la IA y la búsqueda se superponen cada vez más, vale la pena reevaluar cómo se utilizan estas herramientas y si esta unión impía presenta nuevos riesgos. Safiya Umoja Noble ha sido una voz importante en IA y ética de búsqueda durante años, y su opinión siempre es esclarecedora. Hizo una agradable entrevista con el equipo de noticias de UCLA sobre cómo ha evolucionado su trabajo y por qué debemos mantenernos fríos cuando se trata de prejuicios y malos hábitos en las búsquedas.