
La compresión eficaz consiste en encontrar patrones para reducir el tamaño de los datos sin perder información. Cuando un algoritmo o modelo puede adivinar con precisión el siguiente dato en una secuencia, demuestra que es bueno para detectar estos patrones. Esto vincula la idea de hacer buenas conjeturas (que es lo que hacen muy bien los modelos de lenguaje grandes como GPT-4) con lograr una buena compresión.
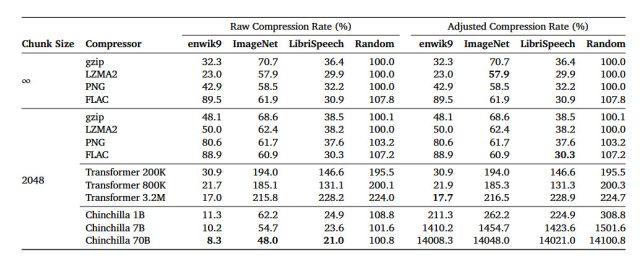
En un artículo de investigación de arXiv titulado «El modelado del lenguaje es compresión», los investigadores detallan su descubrimiento de que el modelo de lenguaje grande (LLM) de DeepMind llamado Chinchilla 70B puede realizar compresión sin pérdidas en parches de imágenes de la base de datos de imágenes ImageNet hasta el 43,4 por ciento de su tamaño original, superando el algoritmo PNG, que comprimió los mismos datos al 58,5 por ciento. Para el audio, Chinchilla comprimió muestras del conjunto de datos de audio LibriSpeech a solo el 16,4 por ciento de su tamaño sin formato, superando la compresión FLAC con un 30,3 por ciento.
En este caso, números más bajos en los resultados significan que se está produciendo una mayor compresión. Y la compresión sin pérdidas significa que no se pierden datos durante el proceso de compresión. Contrasta con una técnica de compresión con pérdida como JPEG, que elimina algunos datos y los reconstruye con aproximaciones durante el proceso de decodificación para reducir significativamente el tamaño de los archivos.
Los resultados del estudio sugieren que, aunque Chinchilla 70B fue entrenada principalmente para manejar texto, también es sorprendentemente efectiva para comprimir otros tipos de datos, a menudo mejor que los algoritmos diseñados específicamente para esas tareas. Esto abre la puerta a pensar en los modelos de aprendizaje automático no solo como herramientas para la predicción y escritura de texto, sino también como formas efectivas de reducir el tamaño de varios tipos de datos.
Mente profunda
Durante las últimas dos décadas, algunos científicos informáticos han propuesto que la capacidad de comprimir datos de manera efectiva es similar a una forma de inteligencia general. La idea se basa en la noción de que comprender el mundo a menudo implica identificar patrones y dar sentido a la complejidad, lo cual, como se mencionó anteriormente, es similar a lo que hace una buena compresión de datos. Al reducir un gran conjunto de datos a una forma más pequeña y manejable manteniendo sus características esenciales, un algoritmo de compresión demuestra una forma de comprensión o representación de esos datos, argumentan sus defensores.
El Premio Hutter es un ejemplo que pone de relieve esta idea de la compresión como una forma de inteligencia. El premio, que lleva el nombre de Marcus Hutter, investigador en el campo de la IA y uno de los autores del artículo de DeepMind, se otorga a cualquiera que pueda comprimir de manera más efectiva un conjunto fijo de texto en inglés. La premisa subyacente es que una compresión de texto altamente eficiente requeriría comprender los patrones semánticos y sintácticos del lenguaje, de manera similar a como lo entiende un humano.
Entonces, en teoría, si una máquina puede comprimir estos datos extremadamente bien, podría indicar una forma de inteligencia general, o al menos un paso en esa dirección. Si bien no todos en el campo están de acuerdo en que ganar el Premio Hutter indicaría inteligencia general, la competencia resalta la superposición entre los desafíos de la compresión de datos y los objetivos de crear sistemas más inteligentes.
En esta línea, los investigadores de DeepMind afirman que la relación entre predicción y compresión no es unidireccional. Plantean que si tienes un buen algoritmo de compresión como gzip, puedes darle la vuelta y usarlo para generar datos nuevos y originales basados en lo que has aprendido durante el proceso de compresión.
En una sección del artículo (Sección 3.4), los investigadores llevaron a cabo un experimento para generar nuevos datos en diferentes formatos (texto, imagen y audio) haciendo que gzip y Chinchilla predijeran lo que sigue en una secuencia de datos después de condicionarlos. una muestra. Es comprensible que gzip no funcionara muy bien, produciendo resultados completamente absurdos, al menos para una mente humana. Demuestra que, si bien se puede obligar a gzip a generar datos, esos datos pueden no ser muy útiles más que como una curiosidad experimental. Por otro lado, Chinchilla, que está diseñada teniendo en mente el procesamiento del lenguaje, como era de esperar, tuvo un desempeño mucho mejor en la tarea generativa.

Mente profunda
Si bien el artículo de DeepMind sobre la compresión de modelos de lenguaje de IA no ha sido revisado por pares, proporciona una ventana intrigante a nuevas aplicaciones potenciales para modelos de lenguaje de gran tamaño. La relación entre compresión e inteligencia es un tema de debate e investigación en curso, por lo que es probable que pronto veamos surgir más artículos sobre el tema.