Google DeepMind
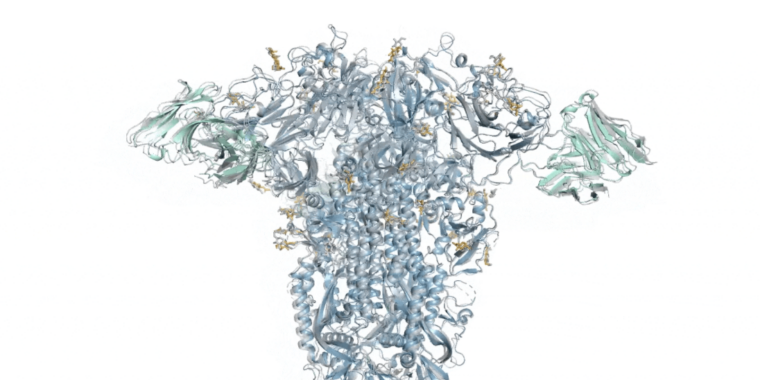
La mayoría de las actividades que tienen lugar dentro de las células (las actividades que nos mantienen vivos, respirando y pensando como animales) están a cargo de las proteínas. Permiten que las células se comuniquen entre sí, ejecuten el metabolismo básico de una célula y ayuden a convertir la información almacenada en el ADN en aún más proteínas. Y todo eso depende de la capacidad de la cadena de aminoácidos de la proteína para plegarse en una forma tridimensional complicada pero específica que le permita funcionar.
Hasta esta década, comprender esa forma 3D significaba purificar la proteína y someterla a un proceso que requería mucho tiempo y trabajo para determinar su estructura. Pero eso cambió con el trabajo de DeepMind, una de las divisiones de inteligencia artificial de Google, que lanzó Alpha Fold en 2021, y un esfuerzo académico similar poco después. El software no era perfecto; tuvo problemas con proteínas más grandes y no ofreció soluciones de alta confianza para cada proteína. Pero muchas de sus predicciones resultaron ser notablemente precisas.
Aun así, estas estructuras sólo cuentan la mitad de la historia. Para funcionar, casi todas las proteínas tienen que interactuar con algo más: otras proteínas, ADN, sustancias químicas, membranas y más. Y, si bien la versión inicial de AlphaFold podía manejar algunas interacciones proteína-proteína, el resto seguían siendo cajas negras. Hoy, DeepMind anuncia la disponibilidad de la versión 3 de AlphaFold, en la que partes de su motor subyacente se modificaron en gran medida o se reemplazaron por completo. Gracias a estos cambios, el software ahora maneja varias interacciones y modificaciones de proteínas adicionales.
Cambio de piezas
El AlphaFold original se basaba en dos funciones de software subyacentes. Uno de ellos tuvo en cuenta los límites evolutivos de una proteína. Al observar la misma proteína en múltiples especies, se puede tener una idea de qué partes son siempre iguales y, por lo tanto, es probable que sean fundamentales para su función. Esa centralidad implica que es probable que siempre estén en la misma ubicación y orientación en la estructura de la proteína. Para hacer esto, el AlphaFold original encontró tantas versiones de una proteína como pudo y alineó sus secuencias para buscar las porciones que mostraban poca variación.
Sin embargo, hacerlo es costoso desde el punto de vista computacional, ya que cuantas más proteínas alinees, más restricciones tendrás que resolver. En la nueva versión, el equipo de AlphaFold todavía identificó múltiples proteínas relacionadas, pero pasó a realizar alineaciones en gran medida utilizando pares de secuencias de proteínas dentro del conjunto de las relacionadas. Probablemente esto no sea tan rico en información como una alineación múltiple, pero es mucho más eficiente desde el punto de vista computacional y la información perdida no parece ser crítica para descubrir las estructuras de las proteínas.
Utilizando estas alineaciones, un módulo de software independiente descubrió las relaciones espaciales entre pares de aminoácidos dentro de la proteína objetivo. Luego, esas relaciones se tradujeron a coordenadas espaciales para cada átomo mediante un código que tenía en cuenta algunas de las propiedades físicas de los aminoácidos, como qué porciones de un aminoácido podían rotar en relación con otras, etc.
En AlphaFold 3, la predicción de las posiciones atómicas se maneja mediante un módulo de difusión, que se entrena dándole una estructura conocida y versiones de esa estructura donde se ha agregado ruido (en forma de cambio de posiciones de algunos átomos). Esto permite que el módulo de difusión tome las ubicaciones inexactas descritas por posiciones relativas y las convierta en predicciones exactas de la ubicación de cada átomo de la proteína. No necesita que le digan las propiedades físicas de los aminoácidos, porque puede descubrir lo que hacen normalmente observando suficientes estructuras.
(DeepMind tuvo que entrenar en dos niveles diferentes de ruido para que el módulo de difusión funcionara: uno en el que las ubicaciones de los átomos se cambiaban mientras la estructura general se dejaba intacta y un segundo en el que el ruido implicaba cambiar la estructura a gran escala del proteína, afectando así la ubicación de muchos átomos).
Durante el entrenamiento, el equipo descubrió que se necesitaban alrededor de 20.000 instancias de estructuras de proteínas para que AlphaFold 3 lograra que aproximadamente el 97 por ciento de un conjunto de estructuras de prueba fuera correcto. En 60.000 ocasiones, comenzó a corregir las interfaces proteína-proteína también a esa frecuencia. Y, lo que es más importante, también empezó a lograr que las proteínas formaran complejos con otras moléculas.