
Imagínese escribir «música de introducción dramática» y escuchar una sinfonía altísima o escribir «pasos espeluznantes» y obtener efectos de sonido de alta calidad. Esa es la promesa de Stable Audio, un modelo de IA de texto a audio anunciado el miércoles por Stability AI que puede sintetizar música o sonidos estéreo de 44,1 kHz a partir de descripciones escritas. En poco tiempo, una tecnología similar puede desafiar a los músicos en sus trabajos.
Si recuerdas, Stability AI es la empresa que ayudó a financiar la creación de Stable Diffusion, un modelo de síntesis de imágenes por difusión latente lanzado en agosto de 2022. No contenta con limitarse a generar imágenes, la empresa se expandió al audio respaldando a Harmonai. un laboratorio de inteligencia artificial que lanzó el generador de música Dance Diffusion en septiembre.
Ahora Stability y Harmonai quieren irrumpir en la producción comercial de audio con IA con Stable Audio. A juzgar por las muestras de producción, parece una mejora significativa en la calidad del audio con respecto a los generadores de audio de IA anteriores que hemos visto.
En su página promocional, Stability proporciona ejemplos del modelo de IA en acción con indicaciones como «música de tráiler épica, intensa percusión tribal y metales» y «lofi hip hop beat melódico chillhop 85 bpm». También ofrece muestras de efectos de sonido generados con Stable Audio, como un piloto de aerolínea hablando por un intercomunicador y personas hablando en un restaurante concurrido.
Para entrenar su modelo, Stability se asoció con el proveedor de música AudioSparx y obtuvo la licencia de un conjunto de datos «que consta de más de 800.000 archivos de audio que contienen música, efectos de sonido y temas de un solo instrumento, así como los metadatos de texto correspondientes». Después de introducir 19.500 horas de audio en el modelo, Stable Audio sabe cómo imitar ciertos sonidos que ha escuchado cuando se le ordena porque los sonidos se han asociado con descripciones textuales de ellos dentro de su red neuronal.
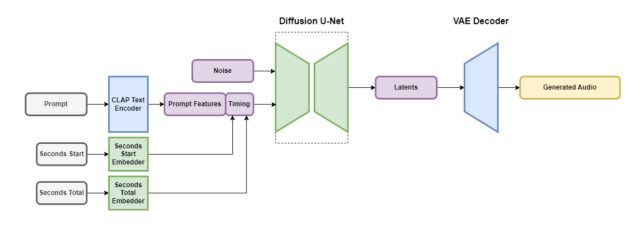
Estabilidad IA
Stable Audio contiene varias partes que funcionan juntas para crear audio personalizado rápidamente. Una parte reduce el archivo de audio de una manera que mantiene sus características importantes y elimina el ruido innecesario. Esto hace que el sistema sea más rápido para enseñar y crear nuevo audio. Otra parte utiliza texto (descripciones de metadatos de la música y los sonidos) para ayudar a guiar qué tipo de audio se genera.
Para acelerar las cosas, la arquitectura Stable Audio opera en una representación de audio comprimida y muy simplificada para reducir el tiempo de inferencia (la cantidad de tiempo que tarda un modelo de aprendizaje automático en generar una salida una vez que se le ha dado una entrada). Según Stability AI, Stable Audio puede reproducir 95 segundos de audio estéreo de 16 bits a una frecuencia de muestreo de 44,1 kHz (a menudo llamada «calidad de CD» porque coincide con las especificaciones técnicas del formato de CD) en menos de un segundo en una Nvidia A100. GPU. La A100 es una GPU de centro de datos robusta diseñada para uso de IA y es mucho más capaz que una GPU de juegos de escritorio típica.
Si bien el audio generado puede cumplir con las especificaciones del CD en profundidad de bits y frecuencia de muestreo, vale la pena señalar que la calidad de percepción real de la música que produce Stable Audio puede variar enormemente, particularmente porque el audio se genera a partir de una representación comprimida en el conjunto de datos.
Como mencionamos, Stable Audio no es el primer generador de música basado en técnicas de difusión latente. En diciembre pasado, cubrimos Riffusion, una versión para aficionados de una versión de audio de Stable Diffusion, aunque sus generaciones resultantes estaban lejos de las muestras de Stable Audio en calidad. En enero, Google lanzó MusicLM, un generador de música con inteligencia artificial para audio de 24 kHz, y Meta lanzó un conjunto de herramientas de audio de código abierto (incluido un generador de texto a música) llamado AudioCraft en agosto. Ahora, con audio estéreo de 44,1 kHz, Stable Diffusion está subiendo la apuesta.
Stability dice que Stable Audio estará disponible en un nivel gratuito y en un plan Pro mensual de $12. Con la opción gratuita, los usuarios pueden generar hasta 20 pistas por mes, cada una con una duración máxima de 20 segundos. El plan Pro amplía estos límites, permitiendo 500 generaciones de pistas por mes y duraciones de hasta 90 segundos. Se espera que las futuras versiones de Stability incluyan modelos de código abierto basados en la arquitectura Stable Audio, así como código de capacitación para aquellos interesados en desarrollar modelos de generación de audio.
Tal como están las cosas, parece que podríamos estar al borde de la música generada por IA con calidad de producción con Stable Audio, considerando su fidelidad de audio. ¿Estarán contentos los músicos si son reemplazados por modelos de IA? Probablemente no, si la historia nos ha mostrado algo sobre las protestas de la IA en el campo de las artes visuales. Por ahora, un ser humano puede superar fácilmente cualquier cosa que la IA pueda generar, pero puede que ese no sea el caso por mucho tiempo. De cualquier manera, el audio generado por IA puede convertirse en otra herramienta más en la caja de herramientas de producción de audio de un profesional.