
Mantenerse al día con una industria que evoluciona tan rápidamente como la IA es una tarea difícil. Entonces, hasta que una IA pueda hacerlo por usted, aquí hay un resumen útil de historias recientes en el mundo del aprendizaje automático, junto con investigaciones y experimentos notables que no cubrimos por sí solos.
Esta semana en IA, DeepMind, el laboratorio de investigación y desarrollo de IA propiedad de Google, publicó un documento que propone un marco para evaluar los riesgos sociales y éticos de los sistemas de IA.
El momento en que se publicó el documento, que exige distintos niveles de participación de los desarrolladores de IA, de aplicaciones y de “partes interesadas públicas en general” en la evaluación y auditoría de la IA, no es accidental.
La próxima semana se celebrará la Cumbre de Seguridad de la IA, un evento patrocinado por el gobierno del Reino Unido que reunirá a gobiernos internacionales, empresas líderes en IA, grupos de la sociedad civil y expertos en investigación para centrarse en la mejor manera de gestionar los riesgos de los avances más recientes en IA. incluida la IA generativa (por ejemplo, ChatGPT, difusión estable, etc.). Allí, el Reino Unido planea introducir un grupo asesor global sobre IA inspirado en el Panel Intergubernamental sobre Cambio Climático de la ONU, compuesto por un elenco rotativo de académicos que escribirán informes periódicos sobre desarrollos de vanguardia en IA y sus peligros asociados.
DeepMind está expresando su perspectiva, de manera muy visible, antes de las conversaciones políticas sobre el terreno en la cumbre de dos días. Y, para dar crédito a quien corresponde, el laboratorio de investigación hace algunos puntos razonables (aunque obvios), como pedir enfoques para examinar los sistemas de IA en el «punto de interacción humana» y las formas en que estos sistemas podrían usarse y incrustado en la sociedad.
Gráfico que muestra qué personas serían mejores para evaluar qué aspectos de la IA.
Pero al sopesar las propuestas de DeepMind, resulta informativo observar la puntuación de la empresa matriz del laboratorio, Google, en un estudio reciente publicado por investigadores de Stanford que clasifica diez modelos principales de IA según su apertura.
Calificado según 100 criterios, incluido si su fabricante reveló las fuentes de sus datos de entrenamiento, información sobre el hardware que utilizó, el trabajo involucrado en el entrenamiento y otros detalles, PaLM 2, uno de los modelos insignia de inteligencia artificial de análisis de texto de Google, obtiene un miserable 40. %.
Ahora bien, DeepMind no desarrolló PaLM 2, al menos no directamente. Pero históricamente el laboratorio no ha sido consistentemente transparente sobre sus propios modelos, y el hecho de que su empresa matriz no cumpla con las medidas clave de transparencia sugiere que no hay mucha presión de arriba hacia abajo para que DeepMind lo haga mejor.
Por otro lado, además de sus reflexiones públicas sobre políticas, DeepMind parece estar tomando medidas para cambiar la percepción de que guarda silencio sobre las arquitecturas y el funcionamiento interno de sus modelos. El laboratorio, junto con OpenAI y Anthropic, se comprometió hace varios meses a proporcionar al gobierno del Reino Unido “acceso temprano o prioritario” a sus modelos de IA para respaldar la investigación sobre evaluación y seguridad.
La pregunta es: ¿es esto meramente performativo? Después de todo, nadie acusaría a DeepMind de filantropía: el laboratorio obtiene cientos de millones de dólares en ingresos cada año, principalmente al otorgar licencias de su trabajo internamente a los equipos de Google.
Quizás la próxima gran prueba ética del laboratorio sea Gemini, su próximo chatbot de IA, que el CEO de DeepMind, Demis Hassabis, ha prometido repetidamente que rivalizará con el ChatGPT de OpenAI en sus capacidades. Si DeepMind desea ser tomado en serio en el frente ético de la IA, tendrá que detallar completa y minuciosamente las debilidades y limitaciones de Gemini, no solo sus fortalezas. Sin duda estaremos observando de cerca para ver cómo se desarrollan las cosas en los próximos meses.
Aquí hay algunas otras historias destacadas de IA de los últimos días:
- Un estudio de Microsoft encuentra fallas en GPT-4: Un nuevo artículo científico afiliado a Microsoft analizó la “confiabilidad” (y la toxicidad) de los modelos de lenguajes grandes (LLM), incluido el GPT-4 de OpenAI. Los coautores descubrieron que a una versión anterior de GPT-4 se le puede pedir más fácilmente que a otros LLM que emitan textos tóxicos y sesgados. ¡Ay!
- ChatGPT obtiene búsqueda web y DALL-E 3: Hablando de OpenAI, la compañía lanzó formalmente su función de navegación por Internet para ChatGPT, algunos tres semanas después de reintroducir la función en beta después de varios meses de pausa. En noticias relacionadas, OpenAI también hizo la transición de DALL-E 3 a beta, un mes después de presentar la última encarnación del generador de texto a imagen..
- Retadores del GPT-4V: OpenAI está listo para lanzar pronto GPT-4V, una variante de GPT-4 que entiende tanto imágenes como texto. Pero dos alternativas de código abierto se le adelantaron: LLaVA-1.5 y Fuyu-8B, un modelo de la startup bien financiada Adept. Ninguno es tan capaz como GPT-4V, pero ambos se acercan y, lo que es más importante, son de uso gratuito.
- ¿Puede la IA jugar Pokémon?: Durante los últimos años, el ingeniero de software Peter Whidden, con sede en Seattle, ha estado entrenando un algoritmo de aprendizaje por refuerzo para navegar en el primer juego clásico de la serie Pokémon. Actualmente, solo llega a Cerulean City, pero Whidden confía en que seguirá mejorando.
- Tutor de idiomas impulsado por IA: Google está apuntando a Duolingo con una nueva función de Búsqueda de Google diseñada para ayudar a las personas a practicar (y mejorar) sus habilidades para hablar inglés. La nueva función, que se implementará en los próximos días en dispositivos Android en países seleccionados, proporcionará práctica oral interactiva para estudiantes de idiomas que traduzcan hacia o desde el inglés.
- Amazon lanza más robots de almacén: En un evento esta semana, Amazon anunció que comenzará a probar en sus instalaciones el robot bípedo de Agility, Digit. Sin embargo, leyendo entre líneas, no hay garantía de que Amazon realmente comience a implementar Digit en sus instalaciones de almacén, que actualmente utilizan más de 750.000 sistemas robóticos, escribe Brian.
- Simuladores sobre simuladores: La misma semana que Nvidia hizo una demostración de cómo aplicar un LLM para ayudar a escribir código de aprendizaje por refuerzo para guiar a un robot ingenuo impulsado por IA a realizar mejor una tarea, Meta lanzó Habitat 3.0. La última versión del conjunto de datos de Meta para entrenar agentes de IA en entornos interiores realistas. Habitat 3.0 añade la posibilidad de que avatares humanos compartan el espacio en realidad virtual.
- Los titanes tecnológicos de China invierten en su rival OpenAI: Zhipu AI, una startup con sede en China que desarrolla modelos de IA para rivalizar con los de OpenAI y otros en el espacio de la IA generativa, anunció esta semana que ha recaudado 2.500 millones de yuanes (340 millones de dólares) en financiación total hasta la fecha este año. El anuncio se produce en un momento en que aumentan las tensiones geopolíticas entre Estados Unidos y China, y no muestran signos de disminuir.
- Estados Unidos corta el suministro de chips de IA de China: En cuanto al tema de las tensiones geopolíticas, la administración Biden anunció esta semana una serie de medidas para frenar las ambiciones militares de Beijing, incluida una mayor restricción a los envíos de chips de inteligencia artificial de Nvidia a China. A800 y H800, los dos chips de inteligencia artificial que Nvidia diseñó específicamente para continuar enviándose a China, se verán afectados por la nueva ronda de nuevas reglas.
- Las repeticiones de canciones pop realizadas por IA se vuelven virales: Amanda cubre una tendencia curiosa: cuentas de TikTok que usan inteligencia artificial para hacer que personajes como Homer Simpson canten canciones de rock de los años 90 y 2000 como “Smells Like Teen Spirit”. Son divertidos y tontos en la superficie, pero hay un trasfondo oscuro en toda la práctica, escribe Amanda.
Más aprendizajes automáticos
Los modelos de aprendizaje automático conducen constantemente a avances en las ciencias biológicas. AlphaFold y RoseTTAFold fueron ejemplos de cómo un problema persistente (el plegamiento de proteínas) podría, de hecho, trivializarse con el modelo de IA adecuado. Ahora David Baker (creador de este último modelo) y sus compañeros de laboratorio han ampliado el proceso de predicción para incluir algo más que la estructura de las cadenas de aminoácidos relevantes. Después de todo, las proteínas existen en una sopa de otras moléculas y átomos, y predecir cómo interactuarán con compuestos o elementos perdidos en el cuerpo es esencial para comprender su forma y actividad reales. RoseTTAFold All-Atom es un gran paso adelante en la simulación de sistemas biológicos.
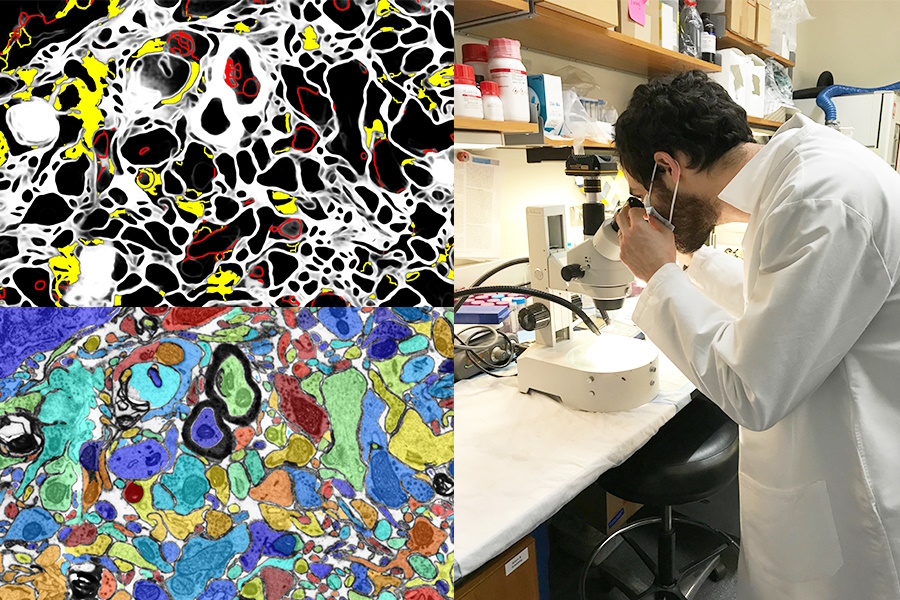
Créditos de imagen: MIT/Universidad de Harvard
Tener una IA visual que mejore el trabajo de laboratorio o actúe como herramienta de aprendizaje también es una gran oportunidad. El proyecto SmartEM del MIT y Harvard colocó un sistema de visión por computadora y un sistema de control de ML dentro de un microscopio electrónico de barrido, que juntos impulsan el dispositivo para examinar una muestra de manera inteligente. Puede evitar áreas de baja importancia, centrarse en áreas interesantes o claras y también etiquetar inteligentemente la imagen resultante.
El uso de IA y otras herramientas de alta tecnología con fines arqueológicos nunca pasa de moda (por así decirlo) para mí. Ya sea que se trate de un lidar que revela ciudades y carreteras mayas o que llena los vacíos de textos griegos antiguos incompletos, siempre es interesante verlo. Y esta reconstrucción de un pergamino que se creía destruido en la erupción volcánica que arrasó Pompeya es una de las más impresionantes hasta el momento.

Tomografía computarizada interpretada por ML de un papiro enrollado y quemado. La palabra visible dice «Púrpura».
Luke Farritor, estudiante de informática de la Universidad de Nebraska-Lincoln, entrenó un modelo de aprendizaje automático para amplificar los patrones sutiles en los escaneos del papiro carbonizado y enrollado que son invisibles a simple vista. El suyo fue uno de los muchos métodos que se intentaron en un desafío internacional para leer los pergaminos, y podría perfeccionarse para realizar un valioso trabajo académico. Mucha más información en Nature aquí. ¿Qué había en el pergamino, preguntas? Hasta ahora, sólo la palabra “púrpura”, pero incluso eso hace que los papirólogos pierdan la cabeza.
Otra victoria académica de la IA está en este sistema para examinar y sugerir citas en Wikipedia. Por supuesto, la IA no sabe qué es cierto o factual, pero puede recopilar a partir del contexto cómo se ve un artículo y una cita de Wikipedia de alta calidad, y buscar alternativas en el sitio y la web. Nadie está sugiriendo que dejemos que los robots ejecuten la famosa enciclopedia en línea dirigida por el usuario, pero podría ayudar a reforzar los artículos para los que faltan citas o los editores no están seguros.

Ejemplo de un problema matemático resuelto por Llemma.
Los modelos de lenguaje se pueden ajustar en muchos temas y, sorprendentemente, las matemáticas superiores son uno de ellos. Llemma es un nuevo modelo abierto entrenado en pruebas y artículos matemáticos que puede resolver problemas bastante complejos. No es el primero: Minerva de Google Research está trabajando en capacidades similares, pero su éxito en conjuntos de problemas similares y su eficiencia mejorada muestran que los modelos «abiertos» (cualquiera que sea el término) son competitivos en este espacio. No es deseable que ciertos tipos de IA estén dominados por modelos privados, por lo que la replicación abierta de sus capacidades es valiosa incluso si no abre nuevos caminos.
Es preocupante que Meta esté progresando en su propio trabajo académico hacia la lectura de la mente, pero como ocurre con la mayoría de los estudios en esta área, la forma en que se presenta exagera el proceso. En un artículo titulado “Decodificación cerebral: hacia la reconstrucción en tiempo real de la percepción visual”, puede parecer un poco como si estuvieran leyendo la mente.

Imágenes mostradas a las personas (izquierda) y la IA generativa adivina lo que la persona está percibiendo (derecha).
Pero es un poco más indirecto que eso. Al estudiar cómo se ve un escáner cerebral de alta frecuencia cuando las personas miran imágenes de ciertas cosas, como caballos o aviones, los investigadores pueden realizar reconstrucciones casi en tiempo real de lo que creen que la persona está pensando o mirando. . Aún así, parece probable que la IA generativa tenga un papel que desempeñar aquí en cómo puede crear una expresión visual de algo, incluso si no corresponde directamente a los escaneos.
Debería ¿Utilizaremos la IA para leer la mente de las personas, si es que alguna vez es posible? Pregúntele a DeepMind; consulte más arriba.
Por último, un proyecto en LAION que por el momento es más aspiracional que concreto, pero igualmente loable. El aprendizaje contrastivo multilingüe para la adquisición de representación de audio, o CLARA, tiene como objetivo brindar a los modelos lingüísticos una mejor comprensión de los matices del habla humana. ¿Sabes cómo puedes detectar el sarcasmo o una mentira a partir de señales subverbales como el tono o la pronunciación? Las máquinas son bastante malas en eso, lo cual es una mala noticia para cualquier interacción entre humanos y IA. CLARA utiliza una biblioteca de audio y texto en varios idiomas para identificar algunos estados emocionales y otras señales no verbales de «comprensión del habla».